
Category Archives: Security
Samsung tweets out malware warning regarding its TVs, but deletes it soon after

There are two issues here that are of equal importance: First, every single digital device is susceptible to some form of malware or unauthorized access; there is no such thing as a one-hundred percent safe digital device. That being said, some are more susceptible than others. Second, I don’t feel that Samsung deleting the tweet that recommended users scan their QLED TVs indicates anything nefarious; adding another confusing and complex acronym like QLED, which is an incomplete acronym anyway as the ‘Q’ stands for ‘Quantum Dot,’ is much more concerning. While it isn’t the focus of this post, I should add that Quantum Dot technology itself is pretty nifty, as it ostensibly eliminates the need for a backlight and is one step away from the capabilities of OLED, or Organic Light-Emitting Diode, which is one of my favorite technologies when properly applied. You want a paper-thin TV with an image so clear you will fall to your knees and weep? OLED is the way to go; it actually eliminates the backlight since the pixels themselves emit their own light.
That’s an 8K(!) QLED in the header image, but also please remember that if your source video wasn’t filmed in 4K or 8K, it won’t magically appear beautiful on such a TV.
Anyway, back on topic: Samsung claims the reason behind the tweet was simply to inform customers that the option is there and they may want to do the scan once in a while, and I think that’s good advice; I applaud them for that. They later claimed it was deleted because although it was just an advisory tweet, it may raise unnecessary alarms in their customers so they had second thoughts. In a sensationalist world, that also makes sense to me.
The fact is, there is very little malware out there that affects TVs, and those who create destructive software want it to have the biggest impact possible, so writing malware for TVs, even with the installed base Samsung enjoys, isn’t a productive use of the cybercriminal’s time. Additionally, because the TVs run on Samsung’s pseudo-proprietary, lightweight and mostly open-source TizenOS, which is also used in some of its other devices such as smart watches, to provide updatable built-in protection would be trivial.
On top of that, it takes SIXTEEN button presses on a remote to get to the actual malware scan function on a Samsung TV, and the belief is very few people would go through that trouble. They don’t even do that on their PCs when it’s just a few clicks away! That’s anecdotal, by the way: Strangely, I couldn’t find any statistics on how often people actually scan, but if informal surveys in some of my classes are any indication, they don’t do it a whole lot.
But who knows? Maybe TV attacks will become the new undiscovered country for malware authors. Frankly, it doesn’t hurt to scan occasionally, and updating the OS should be standard practice. In Samsung’s case, the best course of action would be to push updates to the TVs on their own, and have them update automatically. If you’d like practical advice and information on security from all aspects, from current federal alerts to info about how to protect your PC and other devices at home, the Computer and Infrastructure Security Administration’s website has tons of it, and putting security into practice is a good idea.
Be safe.
Uh-Oh. Some Samsung phones randomly sending Gallery pics to random people. Randomly.

If you have a Samsung phone, and especially if you are on the T-mobile network, you may want to get ready: there are reports that these phones are randomly sending random pictures from the phone’s image gallery to random people in the phone’s contact list. There are obviously many scary parts to this: Not only is every aspect of it random, including when it happens, what gets sent, and to whom, but there is also no record of the images being sent. So you won’t know it happened until you get a seemingly out-of-nowhere text message from that person you went on one date with telling you to stop sending pictures of your dog dressed up like a minion.
It’s happening only with Samsung’s default messaging app, and the apparent reason it’s happening is carriers are upgrading their services to include what’s known as Rich Communication Services, a framework that is intended to replace SMS, otherwise known as simple messaging service, or the bog-standard text apps we use today. There are many reasons to implement a new platform, the two most prominent being SMS has limited functionality and it has a file size restriction os 2MB for attachments. Considering we send over a trillion text messages a year, it’s understandable demand would be there for something with more capabilities, if not necessarily better, than what it is we are using right now. Not to mention, the original incarnation of SMS was developed all the way back in the ’80s!
But wait – if it has all these additional capabilities, then it would necessarily be better, right? Well, that’s where I’m not so sure. Some of the features the RCS includes are the ability to share your location with contacts and indicate whether or not a message has been read. We already have issues with people expecting immediate responses to text messages, and I feel that capability of seeing when a message is read or even if a person is typing a response is going to lead to a whole new level of negative interpersonal dynamics, especially if they can see where you are! On the other hand, if it can incorporate all the features of other messaging apps in a single application, including things like group chat and video calls, then there are advantages to that as well, I suppose.
Additionally, not all incarnations of RCS are compatible, meaning the one that works on a Verizon phone won’t work on a T-mobile phone, and T-mobile is one of the big supporters of this new protocol, although all carriers are on board to varying levels of commitment. I suspect we’ll see that changing very soon as I believe RCS will become the new standard.
I know my phone has it, because I now have a permanent message on my phone’s lock screen and notification tray to set up WiFi calling, which is another feature of RCS. I haven’t done that because I don’t need WiFi calling, it serves absolutely no purpose (for me anyway, because I have unlimited calling), but that screamed out “You have RCS now!” Speaking of which, I’ve been thinking for a couple of months about joining the dark side and switching to iPhone, which doesn’t have RCS at all but has a much more feature-rich messaging app to begin with, one that already incorporates many of the features RCS is attempting to implement.
If you are concerned, the easy solution is use a different texting app rather than the Samsung default. I’ve done that for a long time, specifically Textra – it has a lot of additional functions that I rarely use but are nice to have when I do. There are many apps to choose from, though, and I’m sure you can find one to suit your needs. You should also turn off all permissions to the default app, regardless of whether you use it or not. I don’t have anything to hide in my phone’s image gallery (really, I don’t), but the idea of random images being sent is just too weird. I turned off permission for not only Samsung’s default messaging app, but Verizon’s as well.
If you’re REALLY concerned, Samsung has a secure folder feature. Time to move those…pics. YOU know the ones I mean.
The GDPR finally hits IS301.com

Let me be upfront: I’m making a lot of assumptions with that title. Still, you’ve probably noticed that many, if not all, of the online services you use have sent a flurry of emails indicating in one way or another that they are updating their privacy and security policies, and some just come right and state that it’s because of Europe’s new GDPR, or General Data Protection Regulation which goes into effect in just three days. It’s impossible to sum up such a sweeping set of rules in anything close to a brief post, but essentially what they are trying to do is ensure that any company who does business in the European Union protects the data it collects from customers and others, and more importantly give people control over their own data.
This manifests in several ways I’ll touch on here: One is that the vagueness that often accompanies privacy / security policies must be abolished. I’d honestly never thought of it in these terms until the GDPR came around, but some policies sneakily combine disparate policy acceptance into a single action. That’s a complicated way of saying that when you agree to a privacy or security policy, you’re actually agreeing to many things that cover many aspects of data storage and handling. So instead of signing off on each line-item bit of the policy on its own, you’re agreeing to everything in one fell swoop; you can’t tease apart the various components of the agreement based on aspects you agree with and aspects you don’t. So that’s one thing the GDPR aims to fix.
Seriously – have you ever read some of these privacy policies? (Norway has).
It also wants to give users complete control over the data that is gathered and stored about them, and I do mean all aspects. They can give consent for data to be collected and stored, and they can revoke that consent at any time. They can request readable by both man and machine (that’s an important point) reports about what data is being kept about them and have them transmitted to another provider or service. If there is data that is incorrect users can request it be corrected and they can request their data be expunged completely, both of which are required to be done without undue delay.
Finally, at least for this summary, it requires complete transparency when a breach happens, with companies immediately alerting those affected and informing them what can be done to help address the problem. It also attempts to hold companies and services accountable for data breaches, to the tune of immense fines if they happen. According to the section of the GDPR official site that addresses financial penalties:
Amount
If a firm infringes on multiple provisions of the GDPR, it shall be fined according to the gravest infringement, as opposed to being separately penalized for each provision. (83.3)
However, the above may not offer much relief considering the amount of fines possible:
Lower level
Up to €10 million, or 2% of the worldwide annual revenue of the prior financial year, whichever is higher, shall be issued for infringements of:
- Controllers and processors under Articles 8, 11, 25-39, 42, 43
- Certification body under Articles 42, 43
- Monitoring body under Article 41(4)
Upper level
Up to €20 million, or 4% of the worldwide annual revenue of the prior financial year, whichever is higher, shall be issued for infringements of:
- The basic principles for processing, including conditions for consent, under Articles 5, 6, 7, and 9
- The data subjects’ rights under Articles 12-22
- The transfer of personal data to a recipient in a third country or an international organisation under Articles 44-49
- Any obligations pursuant to Member State law adopted under Chapter IX
- Any non-compliance with an order by a supervisory authority (83.6)
As you can see, they are not screwing around, however this is also the part I take issue with. I don’t have a problem with the transparency issues, however as any of my students knows, it is impossible to have one hundred percent security. That would mean no one can get in to utilize or benefit from whatever is being protected. And the split-second one person has access, the door is open to all sorts of potential problems. The vectors for attack and infiltration are so great, it’s a nonstop, every second of every day war to protect data, and if it happens it can’t always be laid on the shoulders of the company; they could be working feverishly to squelch millions of little fires yet someone could still be burned. This is something I feel could really use a revisit, and likely will in the future. There is no way this doesn’t undergo revision and fine-tuning as the years go on.
So how does all of this relate to this website? Only in some very small ways as I don’t actually do business – as it were – over there, over even over here, for that matter, but the website has a potential global reach, so why not jump in on the ground floor?
I was first notified that I had a new ‘Privacy’ entry in settings. Clicking on that showed me the following page:
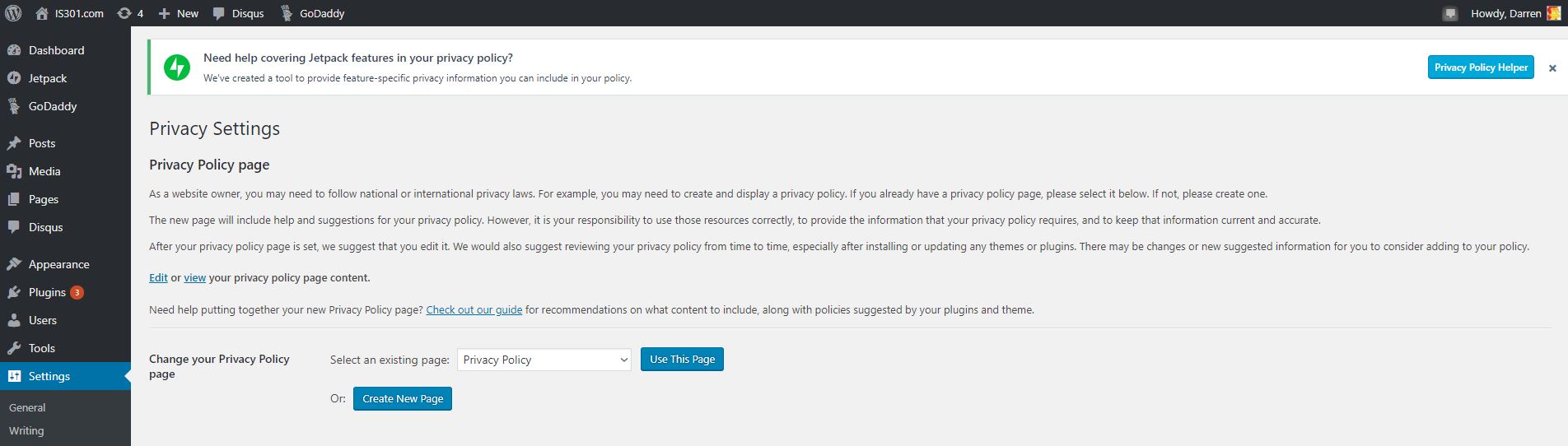
Privacy settings page
You can see in the left sidebar there is an entry called pages, and that’s where separate, standalone pages are developed and managed. Pages such as the ones you see linked across the top of IS301 like ‘About This Site‘ and ‘About Dr. Denenberg.’ It took me a minute to realize this new settings page was telling me I now had an additional page titled ‘Privacy Policy.’ Just to be sure, I went over to the ‘Pages’ section to see, and sure enough, among all the others, there it was.
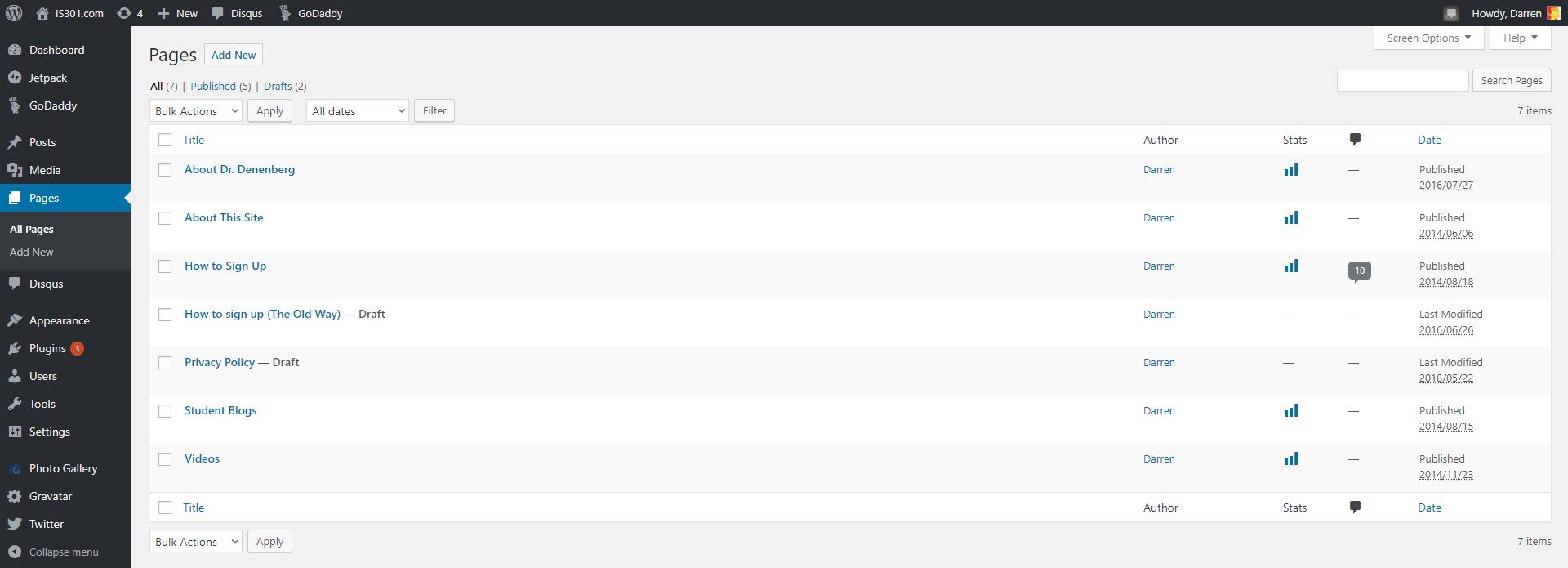
I see you, new security page!
And here’s what it said.
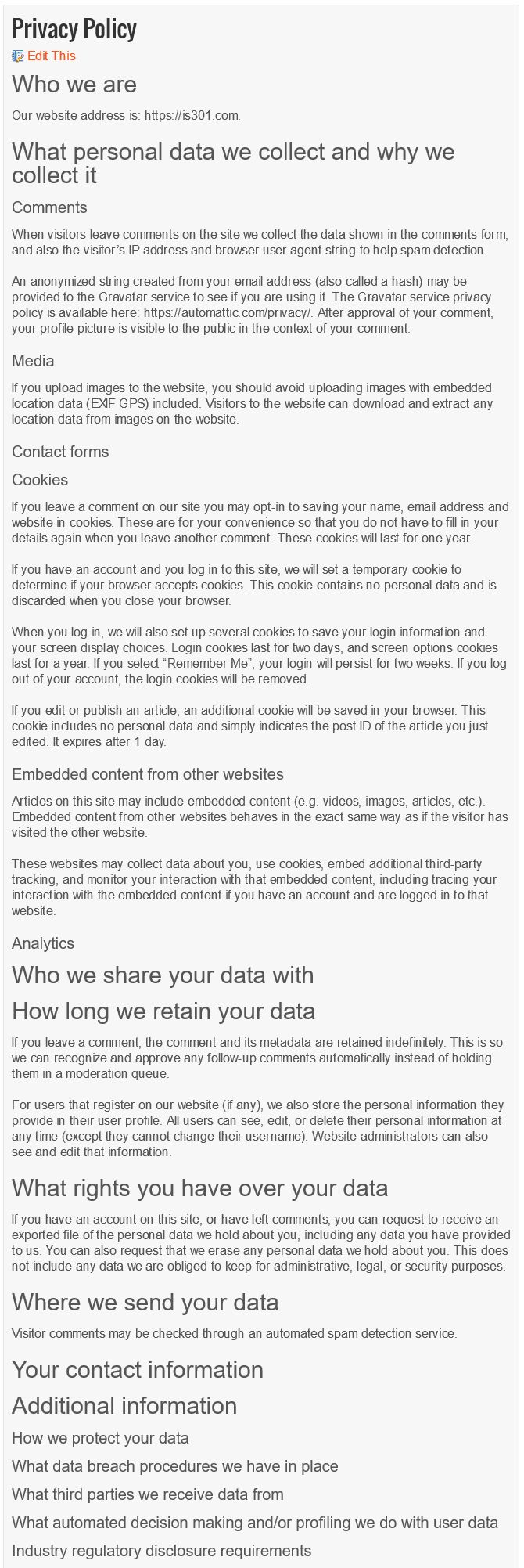
Privacy Page
Very, very generic. Many words, yet says very little. I prefer it has fewer words yet says a lot, so I made some…minor changes.
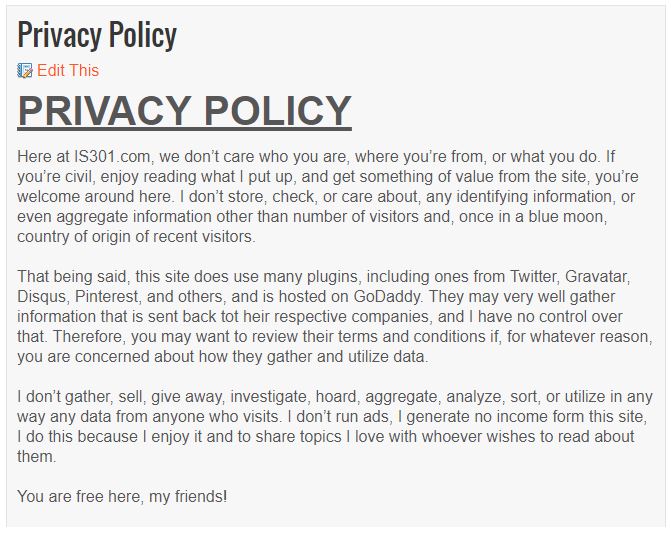
New Privacy Page
Much better. As I said, I don’t do business in the EU, or the US or anywhere else for that matter. Even so, everyone else is preparing, so I may as well. It wasn’t a big deal, but it shows that impact this new legislation is having, from the biggest sites and services on the Internet down to tiny IS301.com.
A new exploit for Intel processors?
Whether or not this turns out to be a big deal is yet to be seen, but research from collaborators at UC Riverside, Binghampton University, Carnegie-Mellon Qatar, and the College of William and Mary, have discovered a new possible exploit in certain Intel processors that they have dubbed BranchScope – that link will take you straight to the research paper itself. The research is published in the Proceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS).
This is a new form of predictive execution exploit, in which the CPU attempts to predict what will happen as the result of a particular instruction, then branch based off of that guess, then guess what will happen as a result of that particular instruction, and so on. It’s the same kind of manner in which a computerized chess game plays chess: Every time you make a move, the game will play out thousands of games as a result of that, trying to guess the moves you will make and the moves it can make in response, and decide on an appropriate next move as a result. It doesn’t make this guess blind, either: In the processor is a component of the Branch Prediction Unit, or BPU, known as a Pattern History Table (PHT) that stores the results of previous operations, and each time a particular branch is taken, the ‘value,’ for lack of a better term, of that branch is increased or decreased. That allows the BPU to be more accurate in its future predictions (Spectre attacked the other part of the BPU, the Branch Target Buffer, which focuses on the result of a branch as opposed to the choice it made).
The exploit, therefore, is to set up selected branches that will modify the PHT and run them so that the PHT will always select one branch over another in a given situation, as well as monitor that the changes to the PHT have actually taken place. These attacks can be used to ensure a particular path is taken when predictive execution happens, and that can be used to divulge information that is otherwise unaccessible, even to the OS, such as key segments, or even provide access to the Software Guard Extensions (SGX), an Intel feature that allows deft software developers to place sensitive or critical data off in protected areas of the CPU cache that should, ideally, be available to none besides the program itself. The whole purpose of the SGX is to prevent bad actors from accessing the data.
Both the Specter vulnerability and BranchScope as well remind me of the more widely-known and difficult to pull off NOP, or No-Operation, Slide (sometimes Sled or Ramp) type of attack, in which an attacker attempts to bypass a series of CPU instructions such that when an operation does happen, it ends up in a specific portion of memory where malicious code has already been installed and will then be run. These often fail, by the way, and in fact the section of memory that holds the malware will often be padded in front and behind so that the target memory location is bigger and the slide hits by luck; it’s a big shot in the dark. The hex value of the NOP is x90, and if you look at the image below which is tracing CPU instruction executions, you can actually see the slide happening as the series of ’90s’ at the top of the lower left and lower right window (source: samsclass).
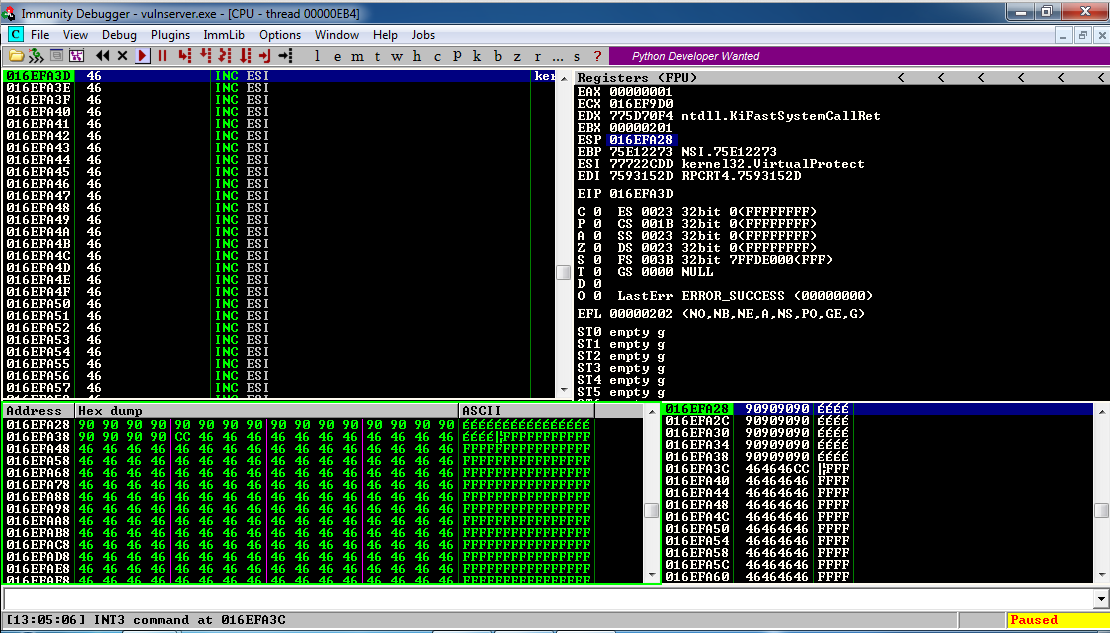
NOP Slide (Lower left). Source: samsclass
This is called a side-channel attack because something is running that shouldn’t be, similar to how loading non-approved, outdated, or unkown-source OSs or apps on a smart phone is considered side-loading.
Predictive execution is complex, the exploits are complex, and as stated earlier, whether or not we see them in the wild is a completely separate issue; the payoff would really have to be worth the effort and I don’t see that being the case unless the exploit was adapted to pair with, say, a trojan horse-style attack, but even then the nature of the returned data would be useless without significant analysis. Knock on wood, but I don’t see this as a common attack vector in the near future.
Has Firefox opted you into any of its studies?
Remember my previous post that talked about the fantastic new version of Firefox, especially the full-screen screenshot capability? I still haven’t adopted it as my main browser, but I was so impressed with th overall changes that were made, I’ve found myself using it more and more; certainly more often than I have in the past. High five for no more memory leaks! Anyway, when I started it up today, it opened to the screen you see below. I was intrigued, especially considering the great improvements they’ve made so far, but as I read through it I also became a little curious. It’s talking about tracking us for usability study purposes, which I’m completely for, but is there anything they perhaps are not telling us? I had no idea the drill down that was about to happen.
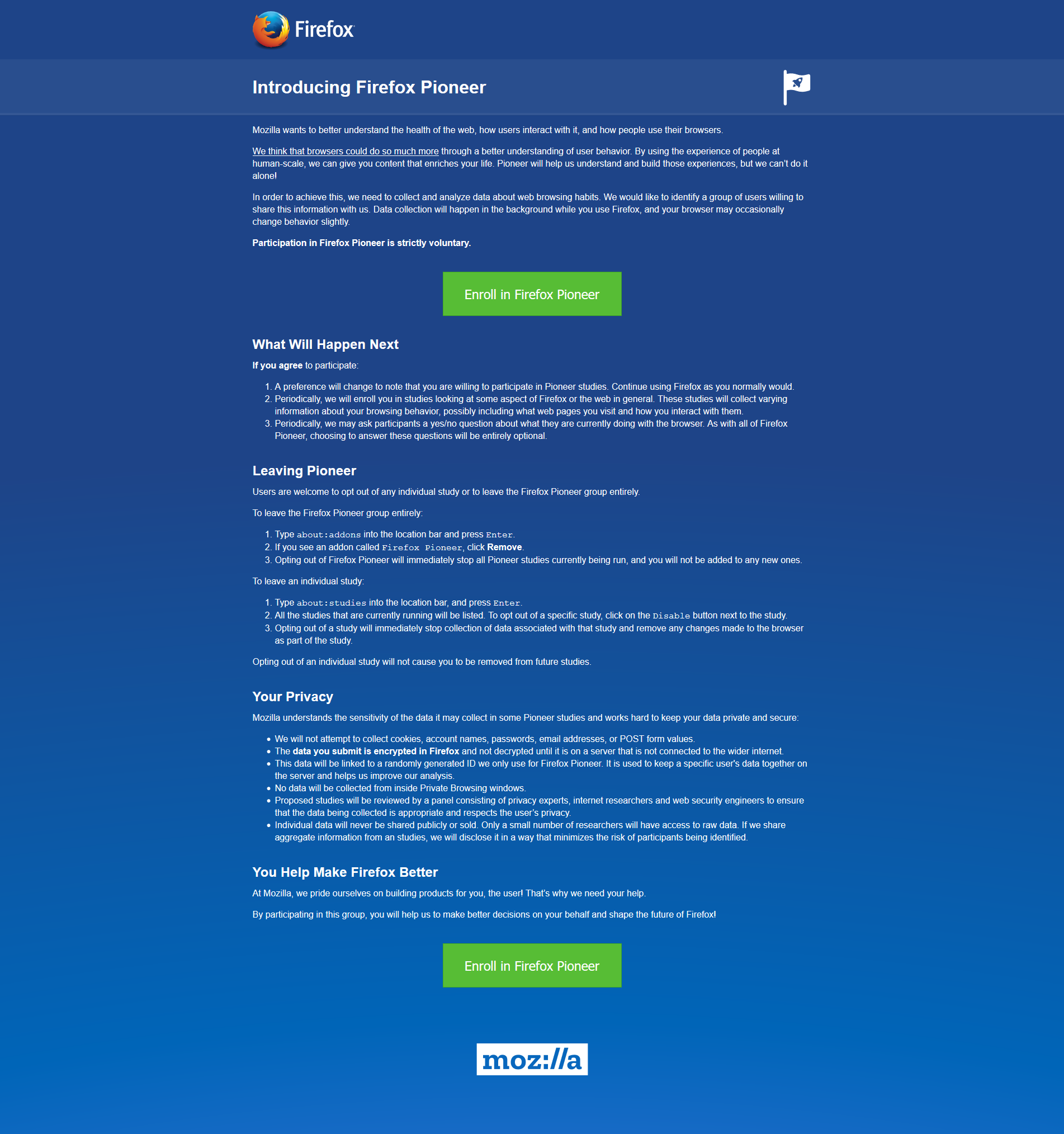
FireFox Pioneer
This is a new initiative called Firefox Pioneer, which aims to discover how people use their browsers, as well as what they vaguely refer to as ‘health of the web.’ They are careful to note that you need to opt in, which is good, and they are pretty clear about what they will and will not do, and what you can expect in terms of privacy, monitoring, opting out, how private sessions play in, and so on. I do get the feeling they are striving for high-level transparency here and acting in good faith, but perhaps a deeper dive into what they could do is warranted.
I should also mention that while Firefox allows for full page screenshots, that option was not available here. I had to open the page in Opera, save it as a pdf which Opera allows compared to Firefox’s screencap capability, open the pdf in Firefox, and then I could save a full-page screenshot. Very curious, but a triumph for ingenuity.
As the page indicates, you can type about:studies into the address bar and see which studies you’re part of, which have completed, and which are available. In fact, you can type about:[topic] into the address bar to discover many interesting things. To see how extensive this capability is, you can see a list at this link. For a real fun time, try about:config – it shows this not at all scary warning, which is really just trying to be funny before letting you access settings. I would normally be for this, however it’s incredibly unclear as to what’s going on if someone isn’t familiar (it fooled me too), especially as it says ‘this application’ and not ‘Firefox.’ Why the pseudo-third person?
Careful now
Clicking ‘I accept the risk!’ takes you to a configuration page that isn’t much better in terms of readability or functionality.
Firefox’s about:config
I don’t usually check this kind of thing, but I certainly should. We all know that companies use your data for many things, sometimes not asking first, so it’s important to keep an eye on what any program you’re using is doing. Typing about:studies showed me this screen, which I have to admit got me to wondering what exactly has been going on behind my back:
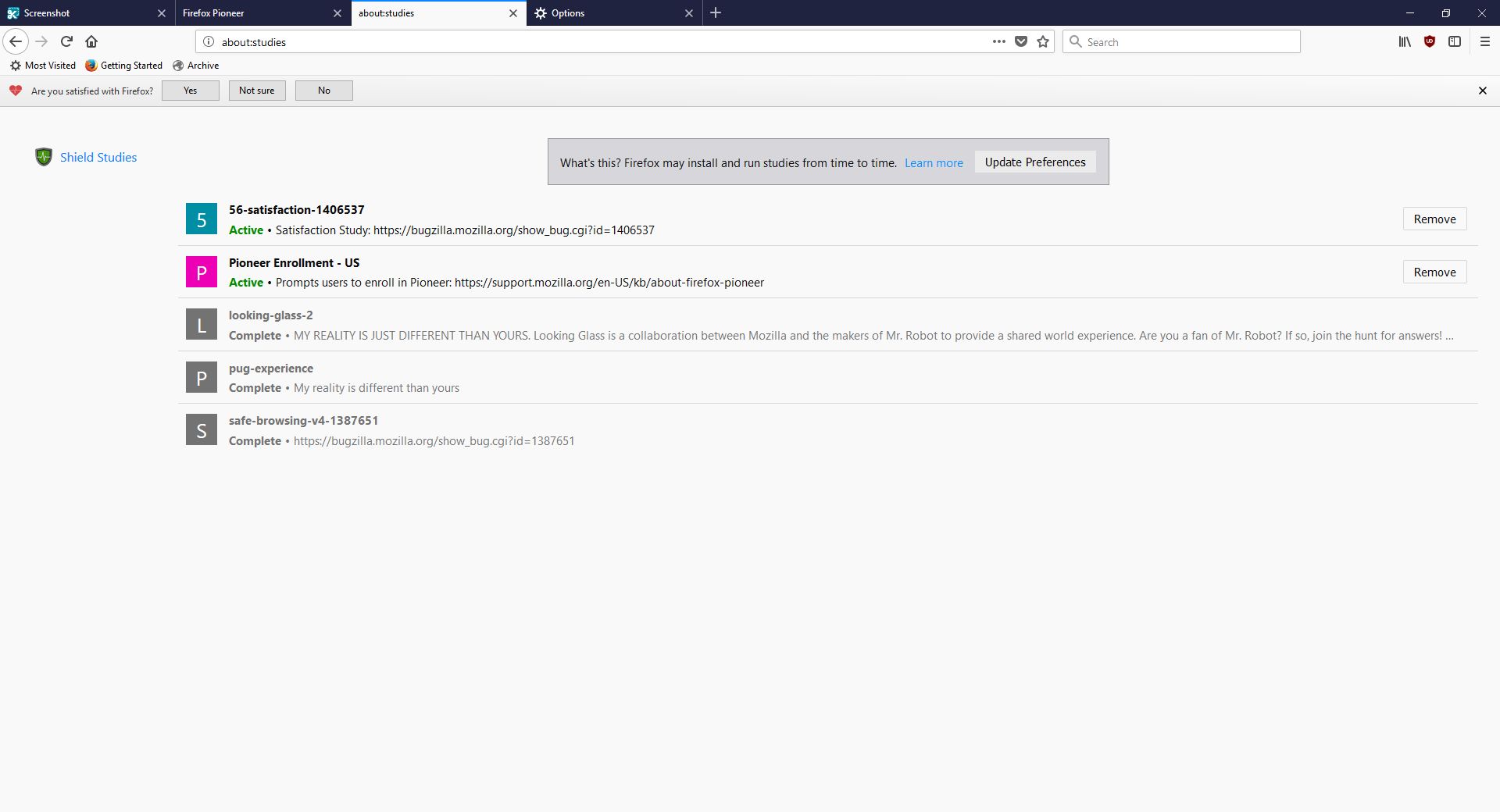
about:studies page in Firefox
A collaboration between Mozilla and the creators of Mr. Robot? Someone’s reality is different than mine? What is going on here exactly? I clicked on Learn More and was taken to their SHIELD page where I learned all about their SHIELD studies, which they claim are to test new features, however from the original request it’s clear they test more than that. I also can’t figure out why it’s capitalized in such a way; I found no evidence it’s an acronym. A deeper dive led me to another Shield page where it’s maddeningly no longer capitalized, and that’s where I found, towards the bottom, a very concerning entry called ‘Normandy – User Profile Matching and Recipe Deployment.’ I wasn’t completely sure what that meant, but it stood out as sounding perhaps not so good. Just the name is curious: If you’re not familiar, and you should be, Normandy happens to be the location in France where the United States, Britain, Canada, and some of France itself launched the D-Day invasion against the Nazis in 1944. Did you ever see Saving Private Ryan? The opening scene was Normandy. I can’t help but wonder why Mozilla has named this bit of its process in such a way. It may be common knowledge, I don’t know, but it was new – and enlightening – to me.
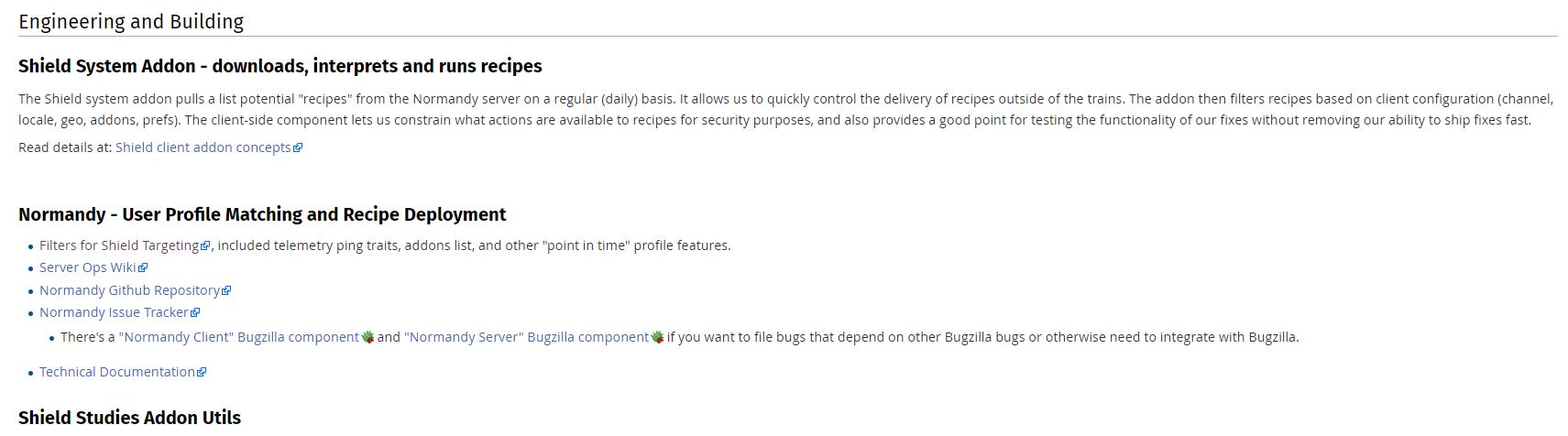
Normandy
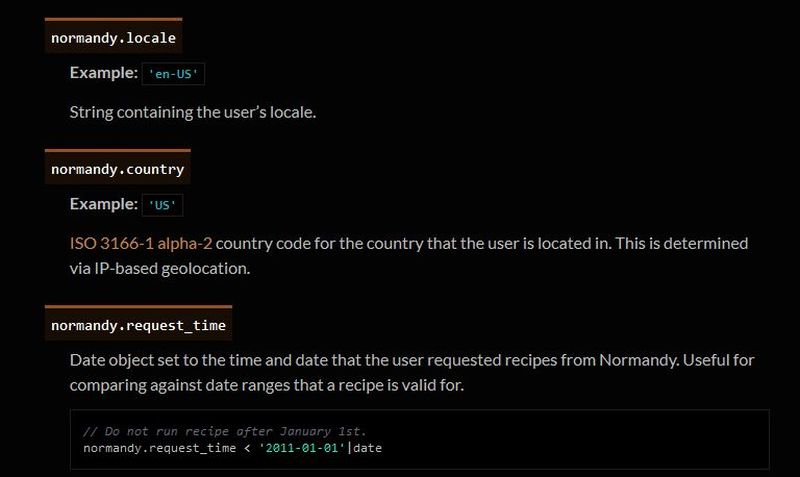
You’ll notice the first item there, “Filters for Shield Targeting.” That took me to another interesting page, the very first paragraph of which states how certain users can be pegged for recipe execution in their browser, and the means by which that is done has access to location and locale (I’m uncertain as to how those differ in Mozilla parlance). It’s further down the page that you begin to see all the ways you can be tracked and monitored.

Filter Expressions
I was going to take a screenshot and crop in the sections that were most troublesome, but there are SO MANY it simply was not possible. To give you an idea, here’s what a screenshot of the page looked like in my image editor. I should also add that from a pure design perspective, they are really not using space efficiently.
![]()
So there’s a Normandy server, and Normandy is also an object that contains what they call ‘general information’ about the client. Client in a case like this should indicate the browser itself, not the person using it, but separating the two is not so easily done, and as a designer / developer, you’re ultimately trying to learn about the user, about their wants, needs and habits, so you can provide a better product. I have no problem with that, and in fact am completely on board with their Heartbeat initiative, but that is relatively benign.
Anyway, back to the above screenshot. They can track a lot, and in the crop below, you’ll see they do something interesting called bucket sampling. I’m intrigued by what this would be used for and how / why / when / etc., so I will have to dig even deeper. I’m guessing it’s some kind of parsing via demographics / usage statistics, but I’m not completely sure. I only found one mention of it on Mozilla’s site, on this page towards the bottom under the heading “Filling the Gap,” but it does lend credence to my assumption. While there’s no formal method known as bucket sampling, it’s something we do, in effect, all the time. I’m looking at you, marketing!

Bucket Sample
So what does all of this have to do with the study that started this whole post? To be quite honest, this rabbit hole didn’t tell me anything I, or any of you, didn’t already know: It’s very easy to track you online, and not just the websites you visit. Where you are, what software you use, what OS you have, whether you’re a new user or experienced, how many mobile and desktop clients you have, how long you stayed at a site, they can even track if you’ve enabled Do Not Track!
And while this sounds like a conspiratorial, tinfoil-hat rant, I actually am not overly bothered by it. I don’t do anything outrageous online other than download Sega Genesis ROMs, because I’m dangerous and like to live life on the edge. But other than that it’s all pretty boring. My issue was mainly that Mozilla may be opting us in to studies without formally informing anyone, and that I just can’t get behind. This was originally going to be a very short post that I thought could be whipped up in about fifteen minutes, but it instead turned into a downhill slalom.
If you’re interested in reading more about Normandy, Mozilla has a helpful website where you can learn all about it and what it can (and does) do, and it really is an interesting, dare I say fascinating, read. http://normandy.readthedocs.io/en/latest/
Oh, one ore thing – In the latest build of Firefox, Mozilla has also made individual cookie management much more cumbersome. I don’t use that feature a lot, but it is definitely not something people should have to go in to the developer console to access. I love the new Firefox, but this isn’t good – user control should be at the center of all commercial software development. Get it together, Mozilla.
Russian botnet master nabbed in Spain, extradited to US

This is a story that has been ongoing for some time. Pyotr Levashov, a well-known and well-established Russian cybercriminal who was arrested in April of last year (2017 if you’re reading this in the distant future – welcome alien overlords!) while vacationing in Spain, has finally been extradited to the U.S. Apparently cybercriminaling does pay well sometimes. The arrest was based on a formal U.S. Department of Justice indictment against him for, among other things, operating the Kelihos Botnet, a long-running, expansive, global botnet that bombarded the world with all kinds of spam for nonsense like get-rich-quick schemes and enhancement medications; if you’re interested, and you should be, you can read the DOJ press release about the indictment and the actual search warrant that allowed for their infiltration of the botnet.
Before we continue, let’s talk about what a botnet is. When malware, or bad software (get it? Mal ware?), is surreptitiously installed on your machine, either through a drive-by attack in which it’s embedded in a Flash ad, or you click on a link or file from a rogue email, or one of many other attack vectors, it will use your machine to carry out tasks without your permission, involvement, or even knowledge. And just to be sure, those tasks it’s carrying out are bad. It can use your machine to send spam, participate in DDoS attacks, store harmful or illegal files, and many other unethical / criminal activities, all without you ever being privy to what’s going on. When that happens, your machine is what’s known as a zombie computer, or more commonly, a bot. Now, imagine hundreds of thousands of these infected machines all acting in unison, for a common goal or under a central control authority. That’s a botnet. Here’s an effective graphic from Reuters that illustrates the architecture of a botnet.
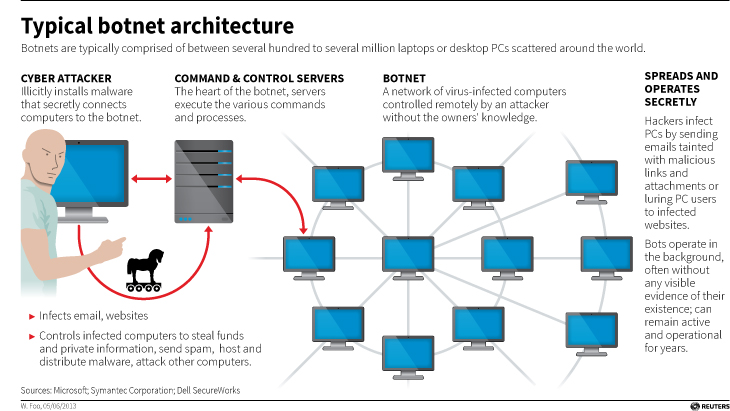
Typical botnet architecture (Source: Reuters)
I wanted to embed an interactive map from Arbor Networks that shows real time attacks happening right now, and provides historical data, but their embed code which uses iframes doesn’t work on WordPress. I find it strange a security firm would still be supplying iframe embed codes, but who am I to judge? No matter; there are other sites that provide similar information using their own honeypot networks, such as Kaspersky’s real-time threat map and the well-known Norsecorp map. Actually, I had intended to use Norsecorp’s IPViking map, however it is now run under HP’s banner, although powered by Norse, and I simply couldn’t get it to work in any browser. Their map linked above works beautifully, though.
Kaspersky’s Threat Map

Norsecorp’s Threat Map
There are several interesting facets to this case: The first is, this guy has been around a long time and was one of the bad actors behind the Storm botnet that first manifested all the way back in 2007. That botnet was eventually dismantled by the combined efforts of Microsoft, malware firms, and the feds, a partnership and collaboration that continues to this day. We’ll come back to this particular botnet soon, because the architecture of these things is going to become important.
By soon, I mean right now! Another interesting aspect to this case is that the botnet was very sophisticated. It used a hybrid structure that is unusual for this kind of thing. Botnets are typically peer-to-peer, in which all the infected machines communicate with each other to coordinate and carry out their nefarious activities, or they use what’s known as a C&C, or Command and Control server, that oversees the whole thing and controls the botnet form a more centralized location. That allows better control and oversight of the bots.
Kelihos, however, was a hybrid, in which there was a C&C server, but there was also a peer-to-peer aspect as there was some autonomy in the architecture that allowed the bots to continuously update among themselves a list of secondary control servers to which they would report, and those would be directly overseen by the main C&C. This is in direct contrast to the Storm botnet mentioned earlier, which was pure peer to peer. A hybrid network also allows for rapid updates to, and distribution of, associated malware.
That leads to the next neat(?) thing about the botnet: It was aggressively and frequently updated. In fact, when a live sinkholing, in which the bots are redirected to to different targets that can then help track the bots or even deactivate them, took place at a 2013 RSA security conference, a new version of the botnet rapidly took its place which indicated that the creators were prepared for just such an emergency and had pre-planned a contingency.
And this was not just a spamming botnet. Along with pushing spam of both the email and desktop pop-up kind, it also stole bitcoin and targeted banks and other large industry outlets with industry specific malware that could rake in millions of dollars while running undetected. For botnet software, this had a wide range of functionalities, both general and specific, although for all it could do it was not hard to track.
The next interesting aspect of this case is Russia fought vigorously against Levashov’s extradition. Not by attempting to block it, but rather by filing an extradition request of their own based on crimes they say he committed in Russia itself. A smart move, regardless of whether the Russian charges are true or an attempt to protect one of their own, that is a clever way of approaching it. It didn’t work, ultimately, and Levashov is now in U.S. custody, but it was an interesting tactic to counter the original extradition request. Not only that, it has happened before.
A really interesting story all the way around, and I’m curious to see how it concludes. In the meantime, be careful, ensure your OS is up to date and fully patched, be sure you are running up-to-date anti-virus and anti-malware protection, try not to visit questionable sites, don’t activate or respond to emails from unknown sources, use an ad-blocker (uBlock Origin is my preferred choice, and I have no connection to them; purely my own opinion), and just generally practice safe computing.
Intel processors revealed to have major flaw, only addressable by OS updates

UPDATE: I’ve been trying to find out more, but Intel is now claiming it has a fix for the vulnerabilities affecting its chips that it will be rolling out by the end of next week. Details are slim, and I will hold off final judgment of course, but I’ll be surprised if it’s completely effective; these microcode patches can be tricky – it’s not a straight firmware update as it impacts the fundamental operation of the CPU. Additionally, it appears the fixes only address the last five year’s worth of processors. Better than nothing if it works.
Original post follows:
This is bad. It has been announced that Intel processors going back approximately ten years have a major flaw in how they separate the system and software. The details have not been released, but the general idea of the problem is already understood for the most part. To give a very high-level overview of what is going on and the impact of how it needs to be addressed, there is a component of every operating system known as a kernel, that separates the hardware from the software. When a program needs to open a port or save a file to disk or access a printer, or utilize hardware in any other way, it hands off that request to the kernel using what’s known as a system call, and the kernel completes the request (user mode to system mode). The catch is, the kernel is hidden from the program, even distributed in various memory locations to further hide it so that it can’t be exploited by malicious actors; it has to be loaded at system boot, however, in order for programs to use it.
Intel processors, though, use a kind of predictive processing, similar to client side prediction in games, in which a guess is made as to what will most likely happen next. In the case of Intel processors, they try to guess what code will be run next and load it up in the queue, however they apparently do this without any security procedures. The kernel is kept separate because it can contain confidential information such as passwords (which is why you can’t even get your own passwords back and there is no way to recover them if lost), however if the CPU provides no security check when loading up predictive code, it could, theoretically, run code that would ordinarily be blocked, which could then give savvy attackers access to low-level system processes and data.
But wait, there’s more bad news! Because this can’t be fixed with a firmware update or anything similar, OSs have to be written to address the problem. Linux, Windows, and OSX will all require updates that relocate the kernel in memory. Normally, it’s available to each program in their own process, but that will no longer be the case, and having to go back and forth between user mode and system mode in this manner will incur a possibly-significant performance hit on a PC after these updates, estimated by some to be as high as 30 percent.
Again, the details aren’t yet fully known, and the impact isn’t either, but if proven true it could be the worst design flaw I have ever seen. I’ll update when more is known.
Almost all HP laptops have a dormant keylogger

If you have an HP laptop like me, you’ll want to read this. For the second time this year, it turns out that (almost) all HP laptops have a deactivated keylogger hidden in their innards. Before, it was a component of the Conexant audio driver and was actually logging keystrokes, while this time it is part of a debugging component for the Synaptics TouchPad software, something most laptops – not just HP – have, so you might want to take a look or inquire with your manufacturer anyway. HP even states on their patch site, linked below, that the driver affects all Synaptics OEM partners, which means there will be a lot more than just HP laptops affected.
While the keylogger is not activated by default, it could be if someone has administrator privileges and knows which specific registry key to edit, a task that is itself no small matter, as anyone who has done registry edits will know. Interestingly, in an odd take on the situation, some in the security field have noted that if someone has administrator access to a machine, they won’t need to modify a registry key to activate a dormant debugger-based keylogger as they could simply install an actual keylogger. The counterpoint is that the driver-based keylogger, because it’s actually part of an integrated debugging / tracing function, would be harder to detect and leave less of a trace than a full-blown logger, so it would be a less intrusive and more opportune choice for those looking to listen in; there’s a built-in excuse for why it might be doing what it’s doing.
That’s assuming it’s detected, of course. The fact is, detecting them is notoriously difficult. Things have gotten better, but even the best antivirus program has trouble identifying them, and that’s even more true of one that’s operating at the system level – you might want to try a scanner that looks for keyloggers specifically. Since nothing is easy, those types of programs are few and far between because of the difficulty in detecting the logger in the first place. The one most often recommended is KL-Detector, but I’m not convinced of its effectiveness and definitely uncertain of the last time it was updated, which is critical in security software. While it will run on Windows 10, the only systems it explicitly confirms are Windows 2000 and XP, not something that gives me confidence as to its currency. Plus, it’s not a removal tool, only a detector. I don’t know why it’s so often recommended.
Physical keyloggers are easy – check where your keyboard plugs into its port. No additional device, no keylogger. Honestly, these are practically obsolete and were mainly used when keyboards still plugged into PS/2 ports, but don’t be fooled – USB physical keyloggers are out there, but are not commonly used because the chance of discovery is high.
It must also be noted that while there are obvious nefarious uses for keyloggers and that is why we generally hear about them, they have valid uses as well. If you are a parent who’s concerned about what your kids are doing online, a keylogger might be one option, especially these days. If you’re conducting a legitimate investigation, a keylogger is an option and has been used in the courtroom, both successfully and unsuccessfully. And, as alluded to above, they have valid testing and debugging uses. It’s similar to peer-to-peer sharing software; we mainly hear about how it’s bad, but it can also be very useful.
In a way it’s better than the previous time this happened because the keylogger is not active, but it’s worse because so many more models are impacted. HP acted right away and issued a patch, although if you received a Windows Update in the last couple of days you should be fine as well. If you’d like to be doubly sure, you can check HP’s patch site to download a patch for your model. There are a lot of links, so you’ll need to know your exact model.
It finally happened

I have the feeling this story could get convoluted. Let me sum up right at the beginning: I have finally received a threatening letter accusing me of copyright infringement, from the Entertainment Software Association (ESA). Some background:
I have been playing vanilla WoW, off and on, for months on a private server known as Elysium-Project. I wrote about the experience not too long ago right here on this site (we’ll get to Felmyst later in this post). The thing about this server is that in order to download the client you have to do so through a torrent, which right away gives the impression of impropriety. I had downloaded it once before, using the uTorrent client, to use on my desktop, and everything seemed above the board.
utorrent client – I probably shouldn’t have started it again for this shot
Recently, though, I downloaded it again, using the exact same torrent client, however this time it was on my laptop. Immediately, even before the file finished downloading, I received the following email from my ISP, Cox Communications:
Dear Customer,
We are forwarding a notice received by Cox Communications which claims that someone using your Cox High Speed Internet service has violated U.S. Copyright law by copying or distributing the copyrighted work listed in the attached complaint. THIS COMPLAINT IS FROM A THIRD PARTY AND NOT FROM COX COMMUNICATIONS. We have included a copy of the complaint, which identifies the party making the claim, the title or work they claim was infringed, and the date of the alleged infringement.
We ask that you review the complaint and, if you believe it is valid, promptly take steps to remove or disable access to the infringing material (typically movies, music, books, or TV shows). If other parties are using your account, such as through your WiFi connection, you should ask them to disable file-sharing in peer to peer applications such as BitTorrent, or delete the copyrighted works.
If you disagree with the claims and believe that no one using your Internet service could have been the source of the alleged infringement, please do not contact Cox Communications to resolve this matter. Cox is simply forwarding the notice to you. However, if you have WiFi, please make sure your WiFi connection is secured with a strong password to prevent unauthorized use of your Internet service. In addition, make sure anti-virus software is installed and up to date to help prevent malware infections.
PLEASE NOTE: THE ATTACHED NOTICE MAY CONTAIN A SETTLEMENT DEMAND FOR MONEY OR OTHER TYPE OF OFFER FOR YOU TO CONSIDER. YOU MAY WANT TO CONSULT WITH AN ATTORNEY REGARDING YOUR RIGHTS AND RESPONSIBILITIES BEFORE CLICKING ON ANY LINK OR VISITING A WEBSITE LISTED IN THE NOTICE.
The material that you share online or make available for sharing is your responsibility. Cox encourages responsible Internet use, but we do not monitor nor control the information you transmit. We have a policy, however, consistent with the Digital Millennium Copyright Act, to take steps when we receive notifications of claimed infringement. We also have a policy of terminating repeat infringers in compliance with the Digital Millennium Copyright Act Safe Harbor for online service providers.
If we continue to receive infringement claims notices for your account, we may in appropriate circumstances suspend your account, disable your Internet connection, and/or terminate your Internet service.
For information about Cox’s Acceptable Use Policy, including copyright infringement, please refer to:
https://www.cox.com/aboutus/policies.htmlTo learn more about your responsibilities concerning copyrighted material, please refer to our help article at:
https://www.cox.com/copyrightGeneral information & FAQs about DMCA notices:
http://www.respectcopyrights.org/
http://www.riaa.com/toolsforparents.php?content_selector=resources-music-copyright-notices
If you would like to reply to this email, please keep the subject line intact for tracking purposes.
Sincerely,
Cox Customer Safety
— Original Message —
[Part 0:0 (plain text)]
—–BEGIN PGP SIGNED MESSAGE—–
Hash: SHA12017-10-07T03:15:10Z
Entertainment Software Association
601 Massachusetts, NW, Suite 300, West
Washington, DC 20001 USAAttention:
Intellectual Property Enforcement
Website: http://www.theesa.com/wp-content/uploads/2014/12/DMCA-FAQs-Updated-12-2014.pdf
E-mail:
dmca@theesa.comCox Communications
Re: Copyright Infringement by Cox Communications Subscriber
Using IP 98.164.255.62 on 2017-10-07T03:14:58Z (the “Subscriber”)
Reference Number c7ed1b3845618ac0d707Dear Cox Communications:
The Entertainment Software Association (“ESA”) is the U.S. trade association that represents the intellectual property interests of companies that publish interactive games for video game consoles, personal computers, handheld devices, and the Internet (hereinafter collectively referred to as “ESA members”).
A list of ESA members can be found at http://www.theesa.com/about-esa/members/.
Under penalty of perjury, we affirm that ESA is authorized to act on behalf of ESA members whose exclusive copyright rights we believe to have been infringed as described below.ESA is providing this notice pursuant to the Digital Millennium Copyright Act (“DMCA”), 17 U.S.C. section 512, to request that you take immediate action with respect to infringement of ESA member copyrighted works by your Subscriber.
Using the IP address on the date and time referenced in the subject line of this notice, the Subscriber or someone using their account employed a peer-to-peer service or software to distribute one or more infringing copies of ESA members’ games, including the following title:Warcraft (franchise)
Courts in the United States have held consistently that the unauthorized distribution of copyrighted works using peer-to-peer or similar services constitutes copyright infringement.
E.g., MGM Studios, Inc. v. Grokster, Ltd., 545 U.S. 913 (2005); BMG Music v. Gonzalez, 430 F.3d 888, 891 (7th Cir. 2005); Arista Records LLC v. Lime Group LLC, 2010 U.S. Dist. LEXIS 46638, *49 (S.D.N.Y. May 11, 2010This Subscriber should understand clearly that there are serious consequences for infringement.
The Copyright Act in the United States provides for statutory damages of up to $30,000 per work infringed, and up to $150,000 per work for willful infringement.
17 U.S.C. section 504(c).We ask that you work with us to protect the intellectual property rights of ESA members by:
1. Providing the Subscriber with a copy of this notice of copyright infringement, and warning the Subscriber that his or her conduct was unlawful and could be subject to civil or even criminal prosecution.
2. Promptly taking steps to stop the Subscriber’s infringing activity.
3. Pursuant to 17 U.S.C. section 512(i)(1)(A), as appropriate, terminating the account of the Subscriber if your records show that he or she is a repeat copyright infringer.ESA has a good faith belief that the Subscriber’s reproduction and/or distribution of these copyrighted works as set forth herein is not authorized by the copyright owners, their agents, or the law.
The information in this notification is accurate.
Neither ESA nor its members waive any claims or remedies, or their right to engage in other enforcement activities, and all such claims, rights and remedies are expressly reserved.If your Subscriber has additional questions about this notice, we would encourage them to visit http://www.theesa.com/wp-content/uploads/2014/12/DMCA-FAQs-Updated-12-2014.pdf to learn how to delete the infringing material and avoid receiving future notices.
Thank you for your prompt attention to this matter.
Sincerely,
Intellectual Property Enforcement
Entertainment Software Association
Website: http://www.theesa.com/wp-content/uploads/2014/12/DMCA-FAQs-Updated-12-2014.pdf– ————- Infringement Details ———————————-
Title: Warcraft (franchise)
Timestamp: 2017-10-07T03:14:58Z
IP Address: 98.164.255.62
Port: 33768
Type: BitTorrent
Torrent Hash: 2b32e64f6cd755a9e54d60e205a9681d6670cfae
Filename: World of Warcraft 1.12 Client.rar
Filesize: 5197 MB
– ———————————————————————<?xml version=”1.0″ encoding=”UTF-8″?>
<Infringement xmlns=”http://www.acns.net/ACNS” xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xsi:schemaLocation=”http://www.acns.net/ACNS http://www.acns.net/v1.2/ACNS2v1_2.xsd“>
<Case>
<ID>c7ed1b3845618ac0d707</ID>
<Status>Open</Status>
<Severity>Normal</Severity>
</Case>
<Complainant>
<Entity>Blizzard Entertainment, Inc.</Entity>
<Contact>IP-Echelon – Compliance</Contact>
<Address>6715 Hollywood Blvd
Los Angeles CA 90028
United States of America</Address>
<Phone>+1 (310) 606 2747</Phone>
<Email>p2p@copyright.ip-echelon.com</Email>
</Complainant>
<Service_Provider>
<Entity>Cox Communications</Entity>
<Email>abuse@cox.net</Email>
</Service_Provider>
<Source>
<TimeStamp>2017-10-07T03:14:58Z</TimeStamp>
<IP_Address>98.164.255.62</IP_Address>
<Port>33768</Port>
<Type>BitTorrent</Type>
<SubType BaseType=”P2P” Protocol=”BITTORRENT”/>
<Number_Files>1</Number_Files>
</Source>
<Content>
<Item>
<TimeStamp>2017-10-07T03:14:58Z</TimeStamp>
<Title>Warcraft (franchise)</Title>
<FileName>World of Warcraft 1.12 Client.rar</FileName>
<FileSize>5450407230</FileSize>
<Hash Type=”SHA1″>2b32e64f6cd755a9e54d60e205a9681d6670cfae</Hash>
</Item>
</Content>
</Infringement>
—–BEGIN PGP SIGNATURE—–
Version: GnuPG v1iQEcBAEBAgAGBQJZ2Ea9AAoJEN5LM3Etqs/WBF0H/jpN7FftxC1K3kUH9j6jG4IZ
A7abndRK8UZISWGRCmT0Tj7+itlRmvzwo9/ggZl9RxiuIPR8KCr/cHTgIbcimjni
ycdjkB6kLOi6FHOA8FybJCVdLK/hMlVvKum/WG4j4oaYBf0LEtowXM1DT1XU7GEy
0F8gUaL5waoJjXuZsA/p88LUhb3Wpmx4BQ6CpzXo96We/JDd+rIApkUsEq56m71s
4Qy5gK3VQVvd3DxqEFZEfU984RBYB3j8i3RCRrHssLUUa4L02Gp3AYpc0szmcOQ8
ZZAtJTOjkCmBUllxo9LNCwgDDQwtybL/QedED4+amO2h7tlLoYfZtuH6qRshpLM=
=iSCJ
—–END PGP SIGNATURE—–
There’s a lot there, but essentially what it is saying is that I committed a copyright infringement not by downloading the Warcraft client, but by also allowing it to be seeded and therefore distributing it. It’s like drug enforcement; the dealers are the problem much more so than the users.
I also have to say I find some amusement in the otherwise serious nature of this email, in that while the complaint from the ESA was very serious and implied significant fines, federal crime, even possible jail sentences, the portion from Cox essentially says “Hey, this is what we were told, now keep us out of it.”
The fact that it came in late on a Friday night while the file was still downloading also makes it quite clear the whole process was automated, both the email to Cox and their forwarding it on to me.
I blame myself for part of this as I never thought to switch off seeding, and when I tried to connect to the private Elysium server after the client download was complete, I neglected to modify what’s known as a realmlist.wtf file to point to Elysium’s server as opposed to the stock Warcraft server. That means that I was attempting to connect directly to Blizzard at first. That’s not what the complaint was about, it was about the redistribution of their client via torrent, but the fact I made that connection error at first was not lost on me.
I don’t anticipate any major problem from this. The second the file was done downloading I deleted the original torrent file and shut down the torrent client. I don’t like to use my limited bandwidth to seed the downloads of others, and I don’t have anything they would want anyway, especially not on my laptop.
So I am ignoring it for now, and in fact I have done what they asked (demanded) I do. It also leads to an interesting legal issue: If you read my previous post about my early experiences on Elysium, you would know that there had been another private server, Felmyst, that was shut down on its very first day, apparently because they were distributing the client along with the game files (or something like that). Elysium, on the other hand, is able to stay up and running because they don’t distribute the client, and therefore no copyright violations are taking place. That seems strange to me since we are playing on a server that uses entirely Blizzard-created assets, but who knows. A quick Google search indicates I’m far from the only one experiencing this, and the issue of monetary gain versus non-profit can have serious implications and Blizzard’s perspective isn’t always so black and white. They’re both very interesting reads.
What I can surmise is, and as I stated earlier, using the client/game once downloaded, even downloading the client itself, is not illegal; it’s the redistribution that’s the problem.
Don’t redistribute clients via torrent, people.
I am completely OK with this

Now this I have no problem with whatsoever, although it hints at a larger issue. Researchers at University College London have discovered a dormant but massive Twitter botnet comprised of an estimated 350,000 fake accounts that does nothing but tweet out random quotes from Star Wars novels.
They discovered it quite by accident while taking a pure random sample of English-speaking Twitter accounts. It’s important to note the importance of this sampling method, as other methods of sampling might bias the results in favor of those accounts that are more active or have more followers. Their one percent sample resulted in approximately six million accounts.
Once their random sample was complete, they plotted the geographic distribution of these users, and they discovered something curious. Many of the tweets formed an almost perfect rectangle along latitude/longitude lines, including open, uninhabitable places like frozen tundra and bodies of water. They conjecture the shape was deliberate to mimic where English-language tweets are most likely to originate, and hide them within the clutter of legitimate Twitter users Tweet flood.
Upon further investigation, the researchers found another surprise. All these Twitter accounts did was tweet out random passages from Star Wars novels. They also never retweet, they send out very few tweets (around ten total) and list ‘Twitter for Windows Phone’ as the tweet source. As much as I hate to say it, that is also likely a ploy to get them to stay under the radar as much as possible because of that platform’s significantly low user base.

It’s not Twitter, but Darth Vader actually posted this on Instagram. Seriously. He doesn’t even care about that stormtrooper behind him.
Using a machine-learning word association approach (a ‘classifier,’ although classifiers are not limited to word association), it found that actual users had a very wide distribution of word choice, while the bots used words almost entirely related to Star Wars. Additionally, the platform percentages were evenly distributed for the most part among real users while the botnet was one hundred percent Twitter for Windows Phone. When the numbers are examined, the botnet is easy to see.
The authors then discuss the implications. Clearly, a dormant, low-activity Star Wars-themed Twitter botnet is not a big deal. However, if the creator decided to reactivate the botnet in order to create a spam network, send malicious messages, or use it for other nefarious purposes, they could. I personally don’t believe that will happen as it likely would have already, however as the authors also note, the botnet went out of its way to stay under the radar.
One of the things I find most interesting about it all is that the authors hint they found another, even more massive Twitter botnet using the same approach, which they will be reporting on at a later date.
Really interesting stuff, and touches on the impact of social media, machine learning and AI, cybersecurity, and geolocation/geotagging just to start (as well as the curious motivations of this particular botnet’s creator). I very much recommend giving it a read.