
Tag Archives: Firefox
Has Firefox opted you into any of its studies?
Remember my previous post that talked about the fantastic new version of Firefox, especially the full-screen screenshot capability? I still haven’t adopted it as my main browser, but I was so impressed with th overall changes that were made, I’ve found myself using it more and more; certainly more often than I have in the past. High five for no more memory leaks! Anyway, when I started it up today, it opened to the screen you see below. I was intrigued, especially considering the great improvements they’ve made so far, but as I read through it I also became a little curious. It’s talking about tracking us for usability study purposes, which I’m completely for, but is there anything they perhaps are not telling us? I had no idea the drill down that was about to happen.
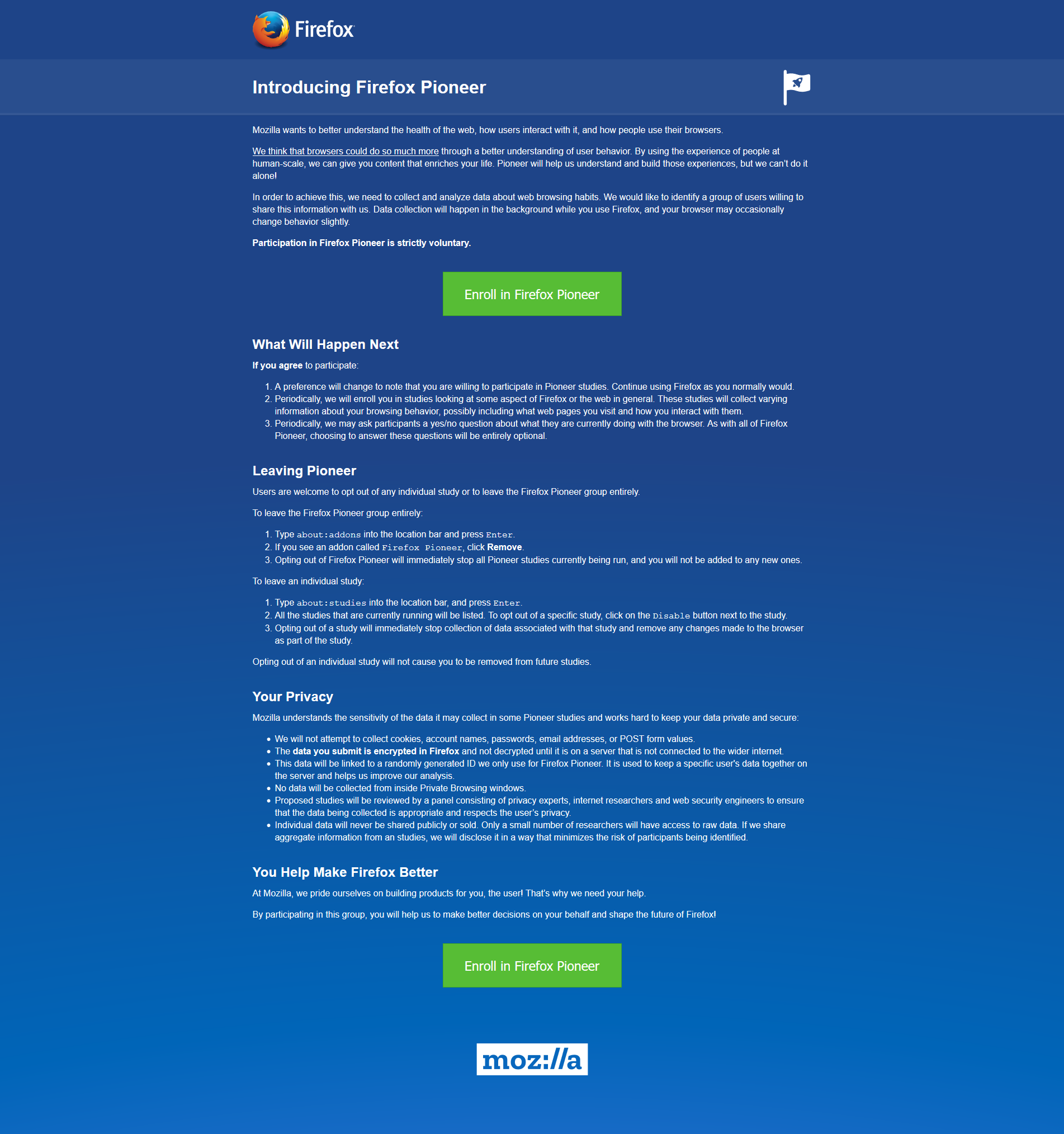
FireFox Pioneer
This is a new initiative called Firefox Pioneer, which aims to discover how people use their browsers, as well as what they vaguely refer to as ‘health of the web.’ They are careful to note that you need to opt in, which is good, and they are pretty clear about what they will and will not do, and what you can expect in terms of privacy, monitoring, opting out, how private sessions play in, and so on. I do get the feeling they are striving for high-level transparency here and acting in good faith, but perhaps a deeper dive into what they could do is warranted.
I should also mention that while Firefox allows for full page screenshots, that option was not available here. I had to open the page in Opera, save it as a pdf which Opera allows compared to Firefox’s screencap capability, open the pdf in Firefox, and then I could save a full-page screenshot. Very curious, but a triumph for ingenuity.
As the page indicates, you can type about:studies into the address bar and see which studies you’re part of, which have completed, and which are available. In fact, you can type about:[topic] into the address bar to discover many interesting things. To see how extensive this capability is, you can see a list at this link. For a real fun time, try about:config – it shows this not at all scary warning, which is really just trying to be funny before letting you access settings. I would normally be for this, however it’s incredibly unclear as to what’s going on if someone isn’t familiar (it fooled me too), especially as it says ‘this application’ and not ‘Firefox.’ Why the pseudo-third person?
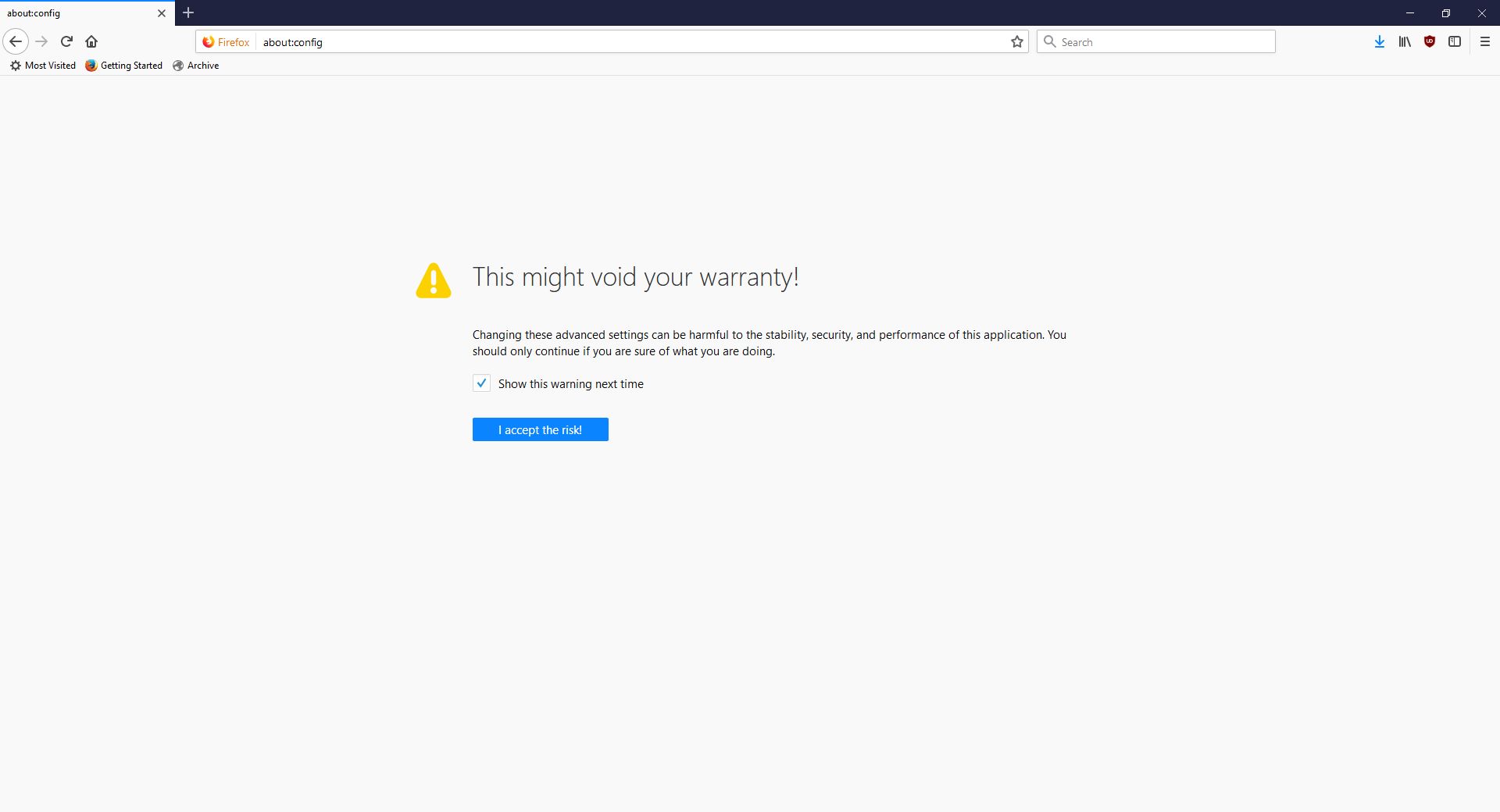
Careful now
Clicking ‘I accept the risk!’ takes you to a configuration page that isn’t much better in terms of readability or functionality.
Firefox’s about:config
I don’t usually check this kind of thing, but I certainly should. We all know that companies use your data for many things, sometimes not asking first, so it’s important to keep an eye on what any program you’re using is doing. Typing about:studies showed me this screen, which I have to admit got me to wondering what exactly has been going on behind my back:
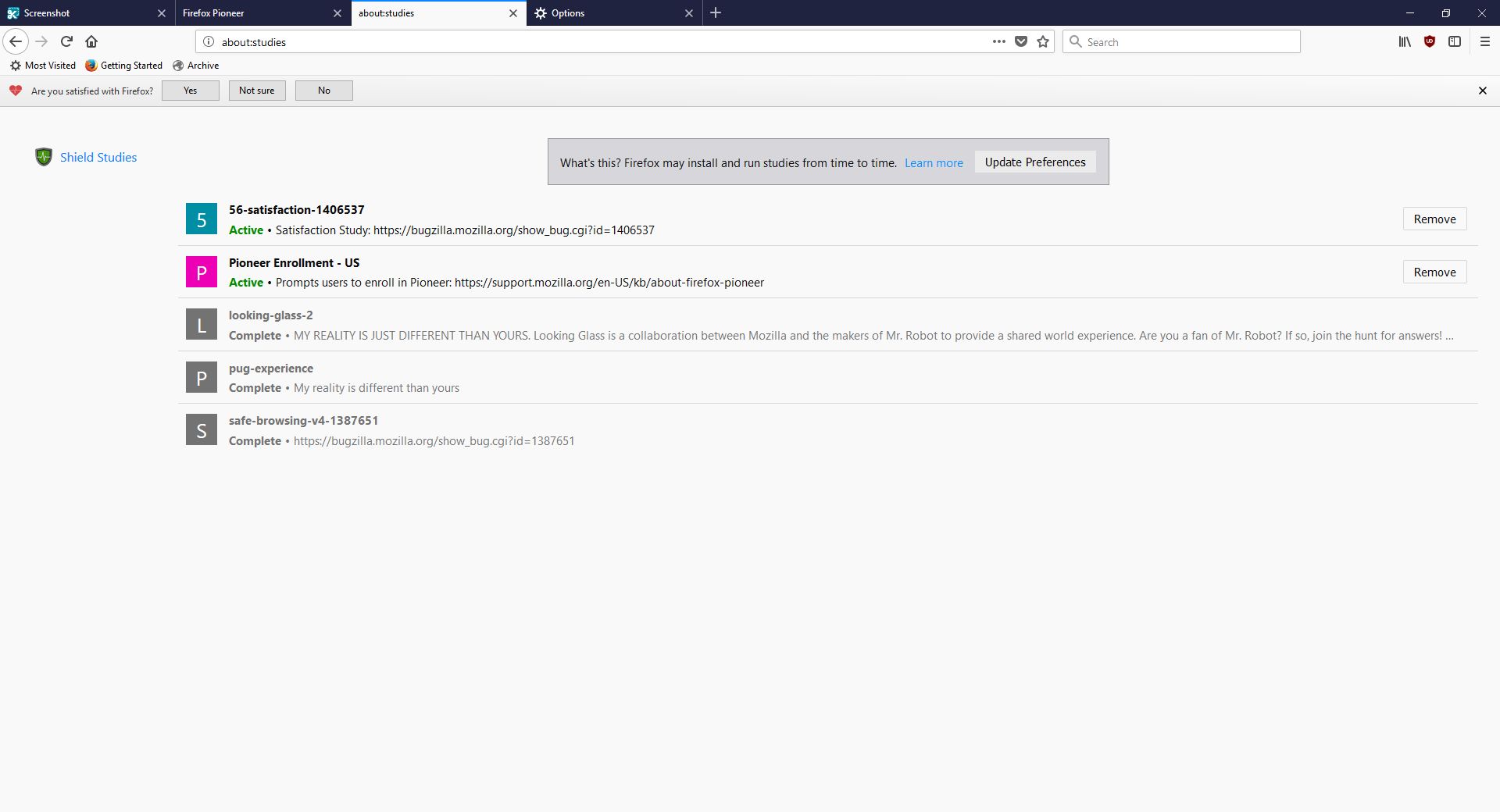
about:studies page in Firefox
A collaboration between Mozilla and the creators of Mr. Robot? Someone’s reality is different than mine? What is going on here exactly? I clicked on Learn More and was taken to their SHIELD page where I learned all about their SHIELD studies, which they claim are to test new features, however from the original request it’s clear they test more than that. I also can’t figure out why it’s capitalized in such a way; I found no evidence it’s an acronym. A deeper dive led me to another Shield page where it’s maddeningly no longer capitalized, and that’s where I found, towards the bottom, a very concerning entry called ‘Normandy – User Profile Matching and Recipe Deployment.’ I wasn’t completely sure what that meant, but it stood out as sounding perhaps not so good. Just the name is curious: If you’re not familiar, and you should be, Normandy happens to be the location in France where the United States, Britain, Canada, and some of France itself launched the D-Day invasion against the Nazis in 1944. Did you ever see Saving Private Ryan? The opening scene was Normandy. I can’t help but wonder why Mozilla has named this bit of its process in such a way. It may be common knowledge, I don’t know, but it was new – and enlightening – to me.
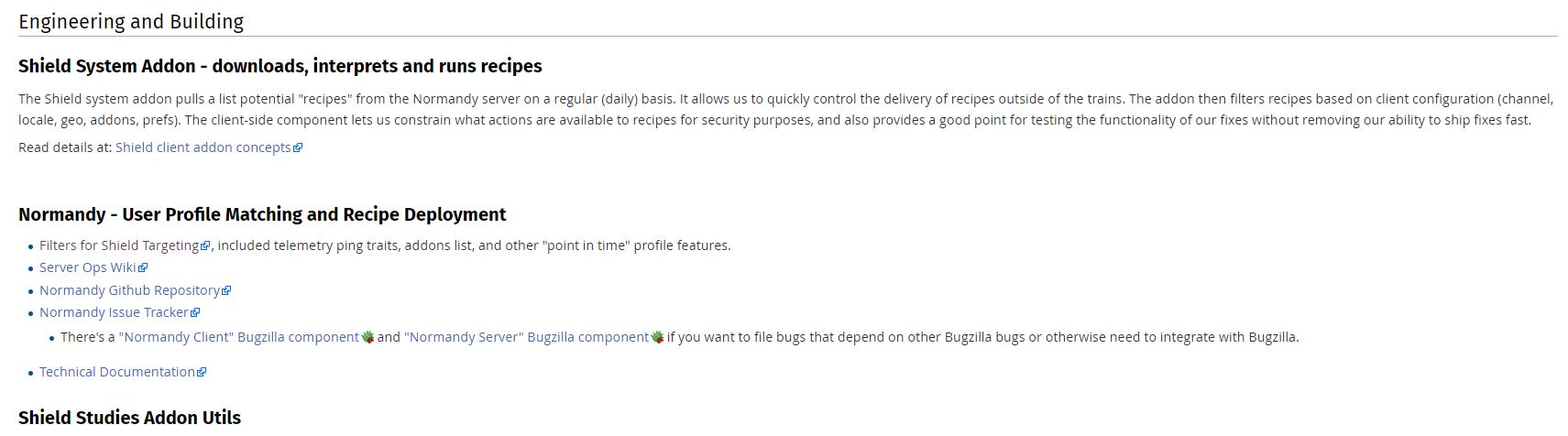
Normandy
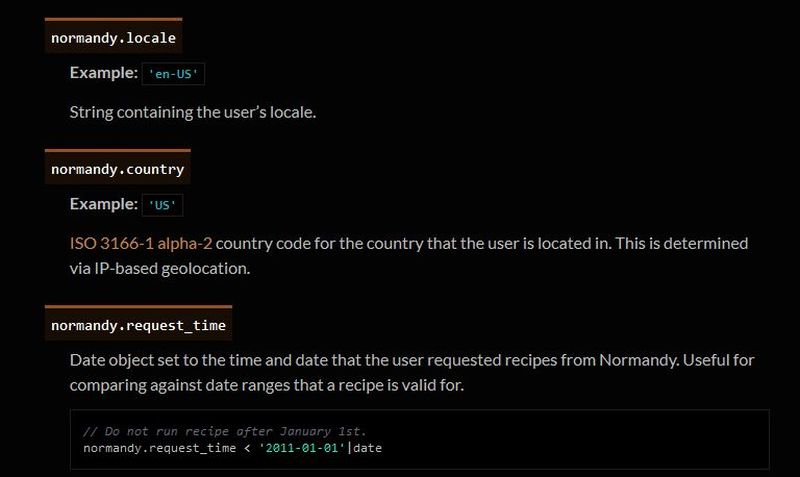
You’ll notice the first item there, “Filters for Shield Targeting.” That took me to another interesting page, the very first paragraph of which states how certain users can be pegged for recipe execution in their browser, and the means by which that is done has access to location and locale (I’m uncertain as to how those differ in Mozilla parlance). It’s further down the page that you begin to see all the ways you can be tracked and monitored.

Filter Expressions
I was going to take a screenshot and crop in the sections that were most troublesome, but there are SO MANY it simply was not possible. To give you an idea, here’s what a screenshot of the page looked like in my image editor. I should also add that from a pure design perspective, they are really not using space efficiently.
![]()
So there’s a Normandy server, and Normandy is also an object that contains what they call ‘general information’ about the client. Client in a case like this should indicate the browser itself, not the person using it, but separating the two is not so easily done, and as a designer / developer, you’re ultimately trying to learn about the user, about their wants, needs and habits, so you can provide a better product. I have no problem with that, and in fact am completely on board with their Heartbeat initiative, but that is relatively benign.
Anyway, back to the above screenshot. They can track a lot, and in the crop below, you’ll see they do something interesting called bucket sampling. I’m intrigued by what this would be used for and how / why / when / etc., so I will have to dig even deeper. I’m guessing it’s some kind of parsing via demographics / usage statistics, but I’m not completely sure. I only found one mention of it on Mozilla’s site, on this page towards the bottom under the heading “Filling the Gap,” but it does lend credence to my assumption. While there’s no formal method known as bucket sampling, it’s something we do, in effect, all the time. I’m looking at you, marketing!

Bucket Sample
So what does all of this have to do with the study that started this whole post? To be quite honest, this rabbit hole didn’t tell me anything I, or any of you, didn’t already know: It’s very easy to track you online, and not just the websites you visit. Where you are, what software you use, what OS you have, whether you’re a new user or experienced, how many mobile and desktop clients you have, how long you stayed at a site, they can even track if you’ve enabled Do Not Track!
And while this sounds like a conspiratorial, tinfoil-hat rant, I actually am not overly bothered by it. I don’t do anything outrageous online other than download Sega Genesis ROMs, because I’m dangerous and like to live life on the edge. But other than that it’s all pretty boring. My issue was mainly that Mozilla may be opting us in to studies without formally informing anyone, and that I just can’t get behind. This was originally going to be a very short post that I thought could be whipped up in about fifteen minutes, but it instead turned into a downhill slalom.
If you’re interested in reading more about Normandy, Mozilla has a helpful website where you can learn all about it and what it can (and does) do, and it really is an interesting, dare I say fascinating, read. http://normandy.readthedocs.io/en/latest/
Oh, one ore thing – In the latest build of Firefox, Mozilla has also made individual cookie management much more cumbersome. I don’t use that feature a lot, but it is definitely not something people should have to go in to the developer console to access. I love the new Firefox, but this isn’t good – user control should be at the center of all commercial software development. Get it together, Mozilla.
And now it’s Opera’s turn

In a recent post, I lauded the new release of Firefox, known as Firefox Quantum, or Firefox 57.0 if you’re in to numbers. The release introduced new features and fixed many issues that have plagued it, in some cases, for years (memory leaks, I’m looking at you). One of the things I really appreciated was the ability to take a full-page screenshot that would capture the whole page, regardless of how much of it was off-screen. For someone like me who uses screenshots in class and on this blog frequently, it’s a godsend.
Having said all that, I also mentioned right at the beginning of that linked post that I’m an Opera guy even though the new Firefox has really narrowed the gap, and since Opera just released version 50.0 with some features of note, I thought it would be only prudent to mention a couple of them here. It won’t get the same coverage as Firefox because it’s not as significant of an upgrade.
Indeed, I’m only going to mention a couple of its features: full-page PDF capture and anti-Bitcoin mining technology.
As I mentioned, Firefox allows for a full-page screencap of a webpage, even if you can’t see it all in the browser window, and the cap is then saved as a .jpg image. As I mentioned, since I use screenshots extensively in my classes and on this very site, that’s invaluable. Now, Opera has the ability to do the same thing except it captures the page as a pdf. It works perfectly, I’ve had no trouble at all, and I can see how it would be useful, especially as opposed to a .jpg. If you wanted a hardcopy version of a recipe, or a series of lessons, or set of instructions then it’s ideal. If you wanted to have a permanent copy of a webpage, or send a copy of it that could be used at a meeting or for whatever reason can’t send a link then it would be very useful there as well, as it would certainly be easier to read then an image. I’m quite impressed with its functionality, and it offers a nice other option alongside Firefox’s full-page .jpg image capture. Both options are fantastic, work flawlessly, and definitely have their own specific use cases. The image below shows a multiple-page post from this site that was saved as a pdf and how it appears; it’s exactly like reading the site itself, but without links. I should also add that Firefox has an advanced ability to select page regions for capture and editing features, a feature not shared by Opera.

Reading a full, multiple-page post as a pdf
The other interesting feature Opera has developed is anti-Bitcoin mining technology. Bitcoins are obviously all the rage, and whether that’s because of the nature of buzzwords or legitimate hype, mining them (a topic far beyond the scope of this post but you can read about at this obvious site) requires extensive use of a PCs resources, somewhere in the neighborhood of one hundred percent, and while smart people will simply build dedicated machines for the task, other smart but misguided people instead want to use yours, and will hijack it through scripts to do so. The obvious downside is that your machine will slow to a crawl and use up insane amounts of power while it tries to mine Bitcoin for someone else. Never fear though, Opera to the rescue. According to their blog, simply turning on their built-in adblocker – another nice feature by the way along with their built-in VPN – will prevent drive-by Bitcoin-mining hijackers.
By the way, I say Bitcoin as a proprietary eponym, like Q-tip or Kleenex, however it’s any type of cryptocurrency mining that gets blocked, and Bitcoin is hardly the only one out there. I should just start saying cryptocurrency as it’s the better, general term, and I’m sure someday I will. Just know that there are many viable brands of this digital currency, but that’s a post for a later time.
So the eternal tug-of-war between Opera and Firefox continues, at least for me, and I couldn’t be happier. I’m thrilled at the way they’ve developed and hope they both keep pushing browsers forward.
The new Firefox browser seems pretty good so far

I’m an Opera guy. Not an ‘opera’ guy, although I have nothing against that particular type of theater, but an Opera browser guy. Many years ago I was a Mozilla Firefox guy, especially as they rose from the once-great Netscape Navigator, however for many years now Opera has been the Samsung Galaxy to Firefox’s iPhone; in other words, Opera always had features that Firefox offered much later or didn’t have at all except through add-ons, and was simply faster, more responsive, more stable, and easier to use. Not only that, Firefox has been infamous for its memory leaks, a problem it was never able to solve (Chrome, too, let’s not forget about Chrome). I should also mention in the issue of fairness that plugins could exacerbate the problem, however the base browser always struggled with the issue as well.
Now, however, Mozilla has released the latest version of its Firefox browser, named Firefox Quantum, and it is the first major update for the browser in almost thirteen years; you can read the blog entry straight from the horse’s mouth here. They claim it’s faster, better, has more features, is better able to manage resources, is compatible with new and emerging web technologies, and has many options for customization and configuration. It’s been redeveloped from the ground up, and it shows.
I gave it a run to see how it is, and it certainly does appear to be better. Very fast, very responsive, clean interface whose elements can be dragged-and-dropped to rearrange them anyway you like, which is very nice. I started up some test sites to see how they loaded, including UCI’s homepage, IS301.com, Amazon, Plex’s homepage as well as my Plex home server, Hackaday.com, eBay, and Rotten Tomatoes. I also left up the default start page.
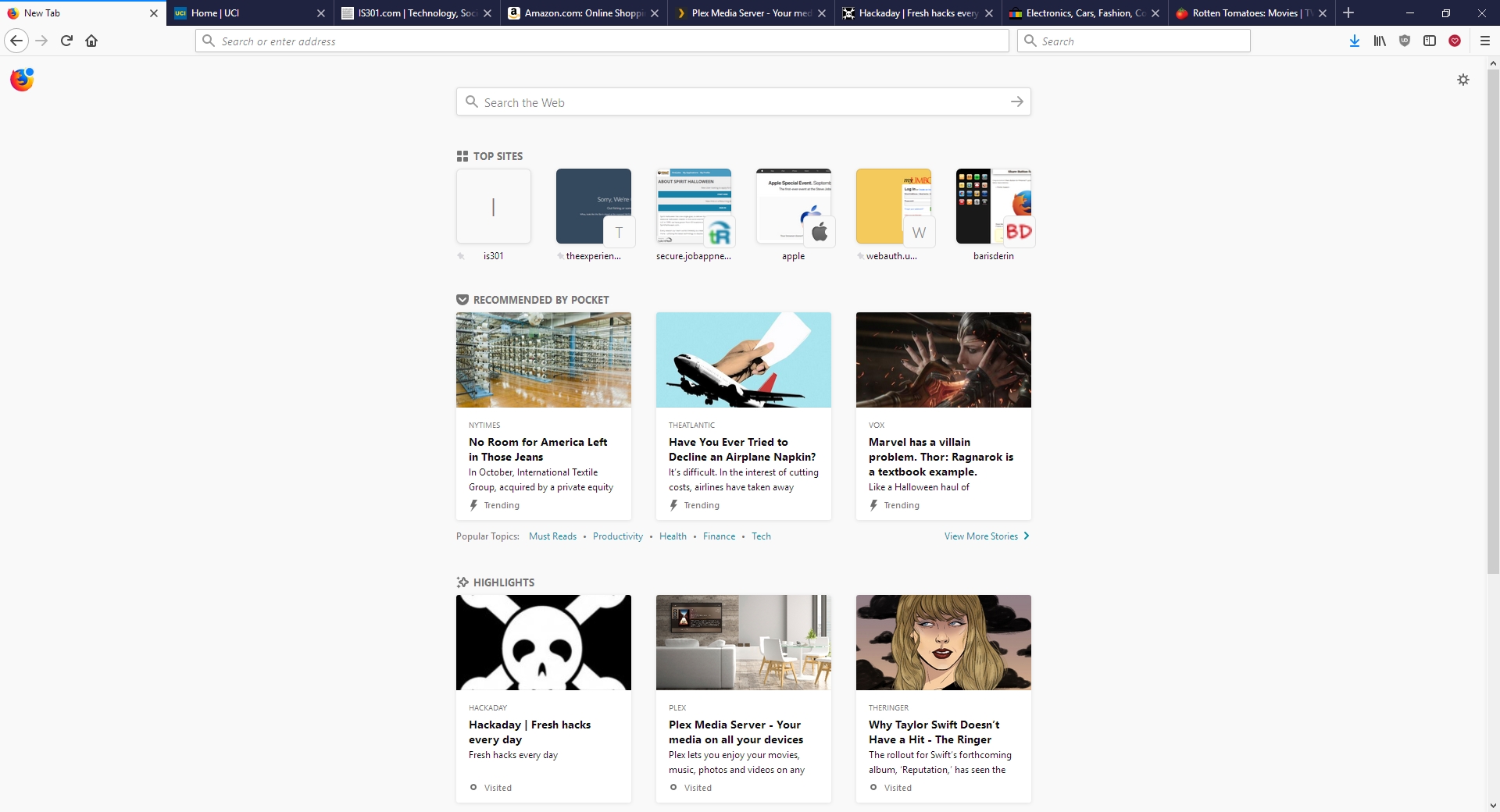
Firefox Quantum
The tabs loaded quickly, although plex.tv and this site took longer than expected, however while comparing response times with Opera, they loaded slowly there as well so the problem was obviously server-side and not an issue with the browser itself; testing them later resulted in equally speedy load times. That wasn’t the case with actually playing videos using Plex, though – Firefox took much, much longer to buffer than did Opera, almost three times as long; I was unable to discern why but the issue was repeatable and consistent. Barring that anomaly, everything else was very snappy and without hesitation. One thing I should add about measuring response times: It is very difficult to do client-side, and is often done via what is known as a stopwatch test, doable in code or with an actual stopwatch. Needless to say, I find those both very unreliable and so went with my own observation to get a general sense of how Opera and the new Firefox compared.
Firefox also has many new features, including deeper integration of Pocket, a personal web-content aggregator that Mozilla bought and integrated a while ago. I have never used it, but can understand how it could be quite beneficial for some. It also has an excellent snapshot feature that allows you to take a screenshot of all or part of a page and save it locally or share it to their cloud service. I don’t know why someone would use the latter, but the former is something I use quite a bit with Opera, and as we will see Firefox does it much better. There is also the aforementioned interface configurations, the library which is just a collection of your browsing history and bookmarks, syncing across devices, and more. As the header image shows, they even have a new icon!
Firefox Features
Of course, that’s where the important issue comes up. The fact is, while the new Firefox browser appears to be much faster, more responsive, more stable, everything I said about Opera earlier, what that essentially does is bring it on par with Opera, except in the case of Firefox’s better screenshot functionality which I will discuss later in the post. I tested each page I loaded in Firefox against the same page as it loads in Opera (with three times as many tabs open in Opera, no less) and the performance was the same. Opera wasn’t better as it had been in the past, it was simply the same. That’s a comment on both Firefox and Opera; how well Opera has been in the past, and the catching up Firefox had to do, and did quite effectively and impressively, to reach it.
As mentioned earlier, there is one big difference in which Firefox easily takes the lead, and regarding a feature I use often – the screenshot feature. Both Opera and Firefox have had this feature for some time, and as stated I use it frequently, although now Firefox’s implementation is much better (MUCH better) – it can identify sections of a screen, such as a headline or picture or other element, as you move your mouse, and snip that out, while Opera requires you to adjust a selection box. Additionally, Firefox has the neat ability to capture a whole webpage as a snapshot, even if parts of it are not visible in your browser – the image below was taken in Firefox even though the entire footer and about 20 percent of the header were not visible when I did. That is a great feature, one that surpasses Opera’s full-screen (note: not full-page) capture, and might be the clincher for some; it almost is for me.

Full-page snapshot using Firefox
Opera, on the other hand, allows for screencaps to be marked up in a very limited fashion right in the capture window, something Firefox does not, however this is less of an issue for me as I usually use GIMP if I need to make extensive edits, and IrfanView if I need to make any size adjustments, batch actions, or simple crops. Good thing, too, since all Opera allows one to do is add some arrows or stickers; Regardless of what Opera says, it’s not actually editing at all. In terms of flexibility, Firefox is the clear winner in this category.
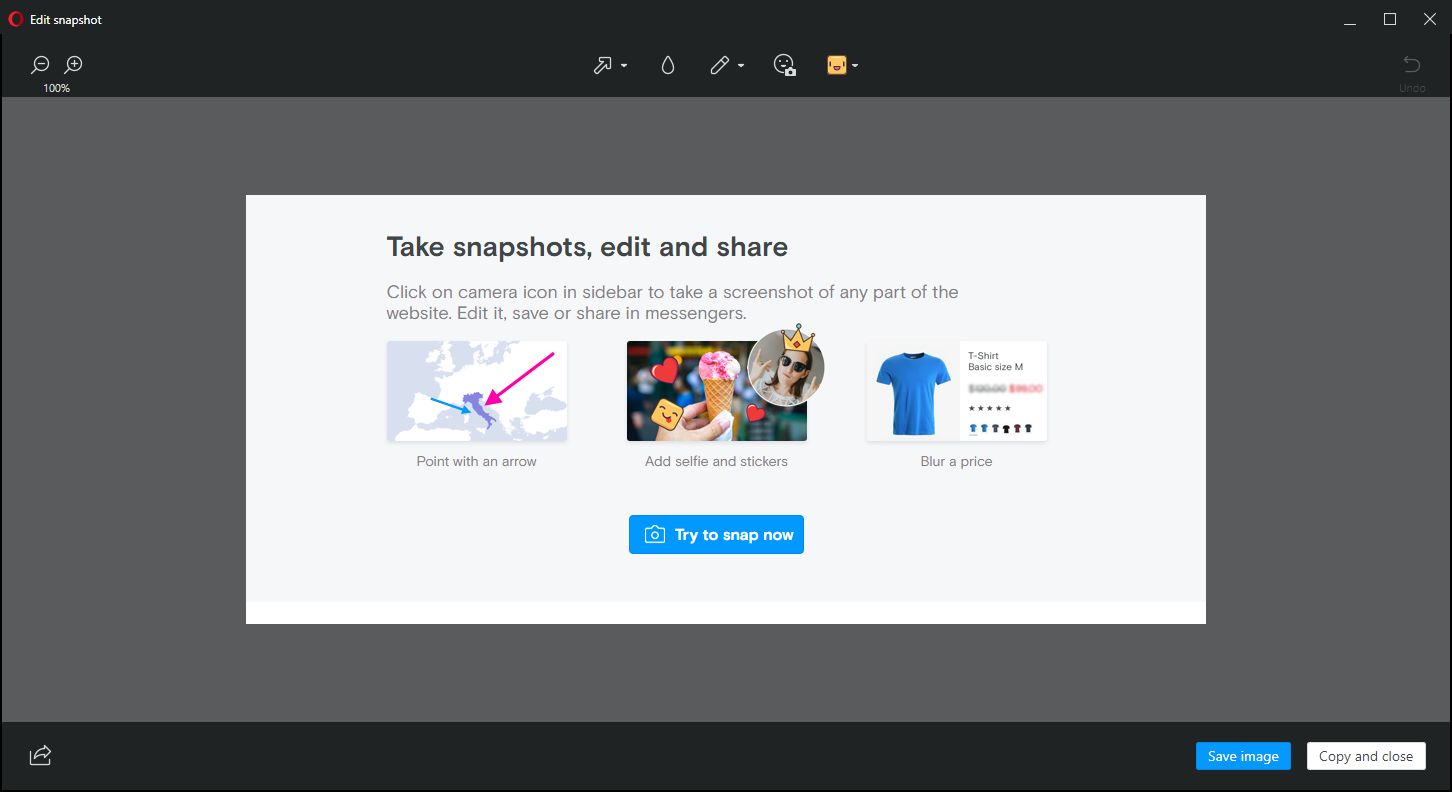
Nice try, Opera
For these reasons, I can and will whole-heartedly recommend Firefox to anyone interested as I think the improvements are significant, but I won’t stop using Opera as it already had many of these features, as well as unit conversion that happens automatically when you highlight a measurement. It also has a customizable, tiled home screen that I find to be very useful; it’s one of my favorite features of Opera and the one I use most often. The new Firefox has something similar, with a single row of six, or double row of twelve, small tiles representing your ‘top sites,’ which can be edited or added to, but not rearranged; ultimately, it’s not as configurable as Opera’s landing page, and very curiously its screenshot functionality is disabled there also.

Opera start page
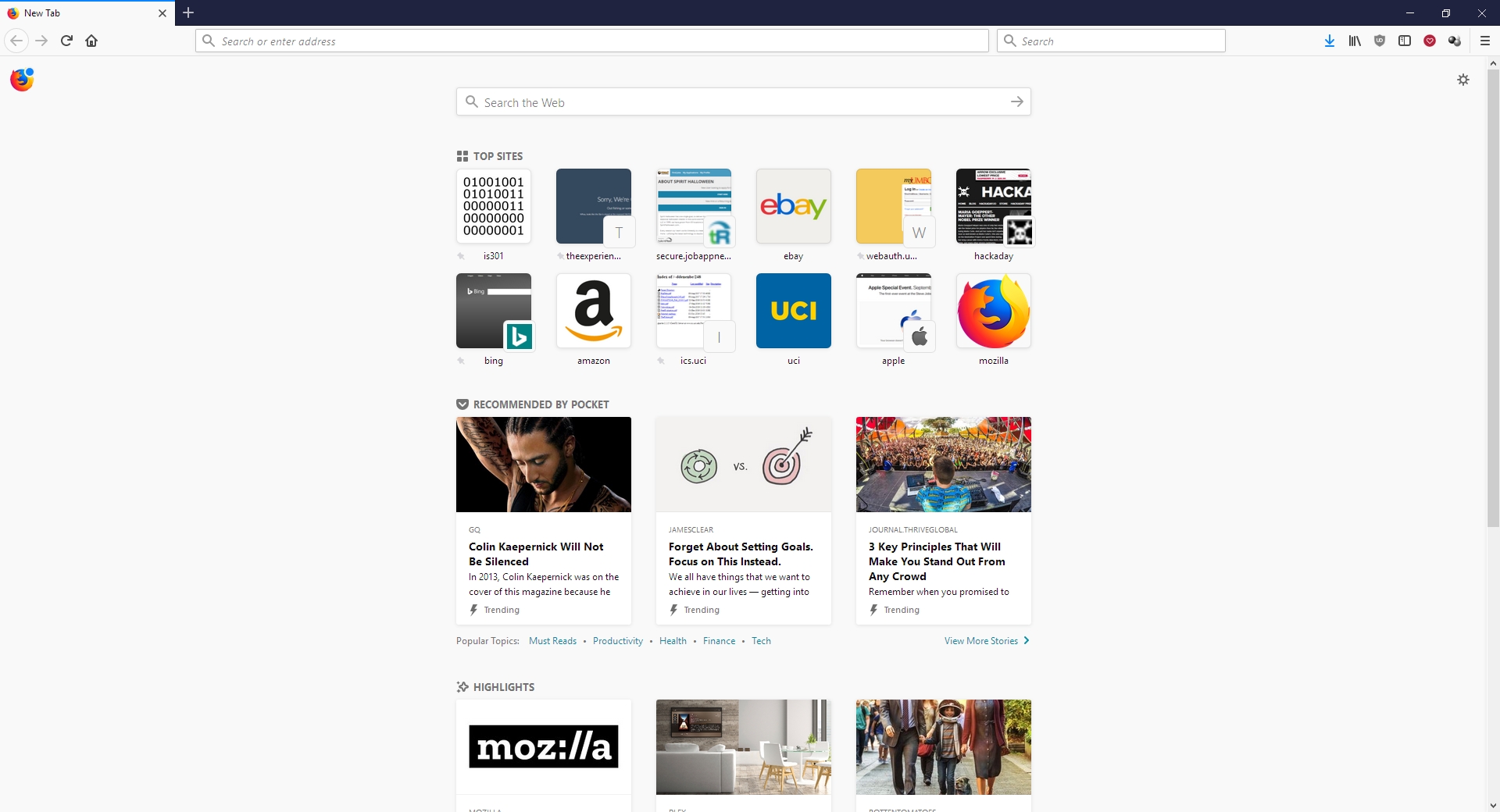
Firefox Start Page
Whichever you prefer, they are now both very good browsers, with the choice being one left up to the preference of the user. I haven’t used Firefox in forever, but I am very pleased to see it in this new form and I hope it continues to get better and better. As I mentioned earlier, I can wholeheartedly recommend it now, something I couldn’t do before, and I will likely use it as a back up browser in place of Chrome, my current backup. There are of course many other choices in browsers, including Vivaldi, Pale Moon (don’t let the terrible web page scare you), and Brave, to name a few, as well as the more well knowns, however here I was only comparing the new Firefox to my main choice. Speaking of which, I was just notified that an update is available for Opera! Here we go…
Firefox, a nifty trick, and alternative browsers

I usually post this exact article after a discussion of memory and memory leaks, especially the one that plagued (although doesn’t any more) FireFox.
Last week in class we talked about the nasty memory leak that has plagued the Firefox browser for years. We learned that ‘memory leak’ is a misnomer because it happens when a program doesn’t release the memory it was using when you close it down. It’s because of that that I moved to what I felt has been the best browser for a long time, Opera. You can read all about the browser in this post I made a long time ago. I was also a fan of the Pale Moon browser, which is the Firefox browser only without the developer tools and therefore without the resultant memory leaks.
Good

Of all the annoyances of using PCs, both Windows-based and Mac, the one that drives me the most insane is dealing with Adobe’s Flash. Flash is the platform that allows everything from video to banner ads to display embedded in a webpage, so if you’ve ever had a video start playing, or a banner ad proclaiming “Swat the fly and win an iPad!” or vicious, malicious software installed on your PC, well, you have Flash to thank for that.
Firefox, some alternative browsers, and a nifty trick
Last night in class we talked about the nasty memory leak that has plagued the Firefox browser for years. We learned that ‘memory leak’ is a misnomer because it happens when a program doesn’t release the memory it was using when you close it down. It’s because of that that I moved to what I felt has been the best browser for a long time, Opera. You can read all about the browser in this post I made all the way back in January. I was also a fan of the Pale Moon browser, which is the Firefox browser only without the developer tools and therefore without the resultant memory leaks.
That being said, I always had a fondness for Firefox. A product of the Mozilla Corporation, itself a part of the non-profit Mozilla Foundation, which had developed the first publicly successful browser, Netscape, it represented a rebirth of sorts for browsers. It also just celebrated its 20th anniversary. Internet Explorer had dominated through what some considered the heavy-handed and even illegal business practices of Microsoft, exacerbated by the fact that Internet Explorer is not, and never has been, a good browser. It’s better now, but it’s still not good. Either way, it successfully defeated Netscape in the first-ever browser wars.
Even so, with the breaking away of the Mozilla foundation and its subsidiaries from parent company America Online, development continued on its internal project, Firefox, and from it was born one of the most successful post-Netscape browsers. It was the first to truly offer competition to Microsoft’s Internet Explorer, and was very popular. A user could download add-ons that enhanced the browser’s functionality (I personally run one that blocks flash ads, automatically starts YouTube videos at their highest available resolution, and provides a very customizable speed dial with multiple groupings which you can see in the image below).
 Then the memory leaks started. Version after version was released, and with each one the leaks became worse. Complaints were lodged to message boards and forums, blog posts and guides were made, articles were written, yet for years and for reasons unknown, they were never addressed. They became so bad that I was forced to choose other browsers, my machines just couldn’t handle the oppressive commandeering of their RAM.
Then the memory leaks started. Version after version was released, and with each one the leaks became worse. Complaints were lodged to message boards and forums, blog posts and guides were made, articles were written, yet for years and for reasons unknown, they were never addressed. They became so bad that I was forced to choose other browsers, my machines just couldn’t handle the oppressive commandeering of their RAM.
Now, however, version 30.0 has been released and I am cautiously optimistic that the problem has been solved. I have gone back to it after years and years, I am very pleased with its interface, its functionality, and most of all its utilization of system resources.
Even with all this, one of Firefox’s most valuable capabilities is the developer tools it provides to allow website designers to evaluate many aspects of a webpage. And now that this release appears to be stable, I have decided to show you a neat Firefox trick using those tools that will let you see the construction of a webpage from a very unique perspective.
First, you’ll need to bring up the developer dashboard. You can do this pressing the Function (Fn) and F12 keys together, or you can click on the options menu which is the three horizontal bars in the upper-right corner of the browser. That will open up the options menu as seen in the screenshot below:
 Click on the ‘Developer Wrench’ at the bottom of that window, then in the new menu that appears click ‘Toggle Tools’ and the developer dashboard will open.
Click on the ‘Developer Wrench’ at the bottom of that window, then in the new menu that appears click ‘Toggle Tools’ and the developer dashboard will open.
Once the dashboard is open, if you are using the newest version of Firefox you will need to click on the small gear at the far left of the developer toolbar, circled in the following screenshot (If you’re using an older version, you can skip this and the next step):
 That will open up a menu with some checkboxes on the left hand side. Scroll down until you see ‘3D view’ under ‘Available Toolbox Buttons’ and check that box if it is unchecked.
That will open up a menu with some checkboxes on the left hand side. Scroll down until you see ‘3D view’ under ‘Available Toolbox Buttons’ and check that box if it is unchecked.
 Once you do that, you will notice a little 3D cube has appeared in the toolbar icons on the right. Again, if you are using an older version of Firefox it will be there by default. I have circled it in the following screenshot:
Once you do that, you will notice a little 3D cube has appeared in the toolbar icons on the right. Again, if you are using an older version of Firefox it will be there by default. I have circled it in the following screenshot:
 Now the fun begins. If you click on that little cube, your page will fall back into the browser and be rendered in 3D. Using your mouse, you can spin the page, you can see it from the top or bottom or even from behind. You can click the little ‘x’ to the far right of the cube to see the page in all its 3D glory, or you can leave the developer tools up. The advantage to developers is that the 3D view actually shows all the individual elements of the page and how much nested HTML (Hypertext Markup Language, the base language in which web pages are developed) they use. In other words, to display an ad, there may be HTML that allocates the space, more HTML that selects an ad, more HTML that ensures the ad is appropriate, more HTML that positions the ad, more HTML that displays the ad, and so on. Each of those layers would be represented. If you click on an element and have the developer dashboard open, the relevant code will be highlighted in the dashboard. Clicking the cube again or pressing escape will return the page to normal (NOTE: Only once that didn’t work, and I had to close then restart the browser, so be aware).
Now the fun begins. If you click on that little cube, your page will fall back into the browser and be rendered in 3D. Using your mouse, you can spin the page, you can see it from the top or bottom or even from behind. You can click the little ‘x’ to the far right of the cube to see the page in all its 3D glory, or you can leave the developer tools up. The advantage to developers is that the 3D view actually shows all the individual elements of the page and how much nested HTML (Hypertext Markup Language, the base language in which web pages are developed) they use. In other words, to display an ad, there may be HTML that allocates the space, more HTML that selects an ad, more HTML that ensures the ad is appropriate, more HTML that positions the ad, more HTML that displays the ad, and so on. Each of those layers would be represented. If you click on an element and have the developer dashboard open, the relevant code will be highlighted in the dashboard. Clicking the cube again or pressing escape will return the page to normal (NOTE: Only once that didn’t work, and I had to close then restart the browser, so be aware).
But don’t listen to me! Try it, and be amazed. It works on any page. Here are some screenshots of this blog with the 3D view in full force.




You can even view the page from behind!

Below you can see a page element highlighted, and the related HTML highlighted in the dashboard underneath.
